高速缓冲存储器 Cache
Cache 的相关基本概念

- 定义与作用: Cache 是位于 CPU 和主存之间的高速小容量存储器,用于弥补 CPU 与主存之间的速度差异,提高系统整体性能。它存储了 CPU 最近或最频繁访问的数据和指令。
- 局部性原理:
- 时间局部性: 指程序在执行的近期,对某个数据或指令的访问,很可能在不久的将来再次访问该数据或指令。
- 空间局部性: 指程序在执行的近期,对某个数据或指令的访问,很可能在不久的将来访问其周围地址的数据或指令。Cache 的设计和效率正是基于这两种局部性原理。
Cache 系统的性能评价
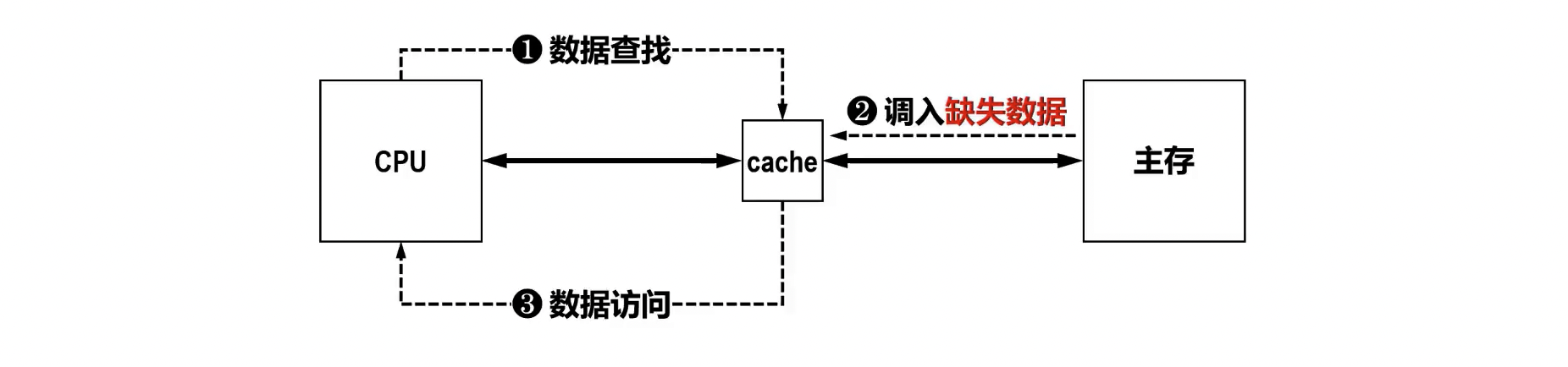
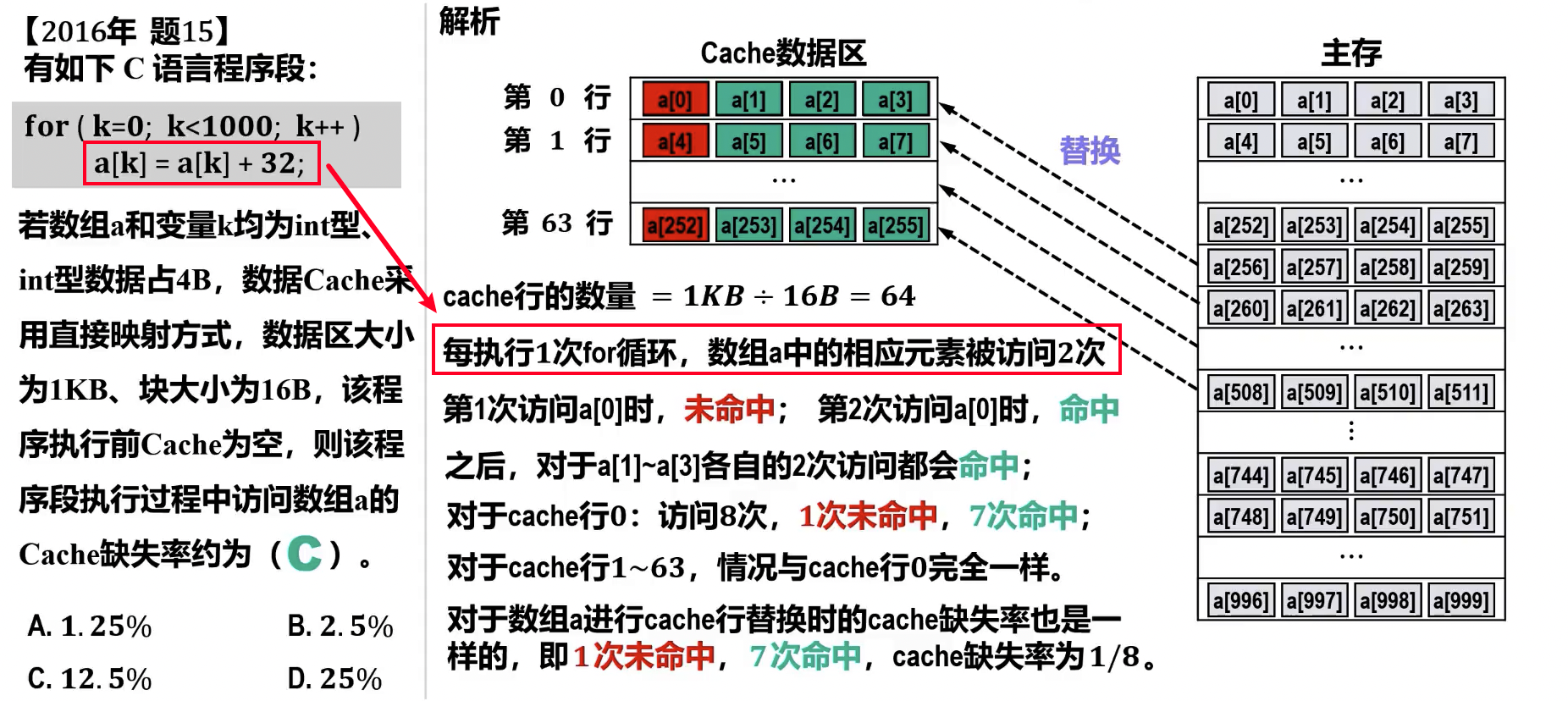
- Cache 行/块 (Cache Line/Block): Cache 和主存之间数据交换的基本单位。一个 Cache 行通常包含一个主存块的数据,并附带控制信息,如标记位、有效位、脏位等。
- 缺失数据相邻的数据也会随着数据块一起载入 cache
- 预读策略可以充分利用程序的空间局部性,提高顺序访问的命中率。然而,数据块的大小对 cache 有较大影响:
- 数据块过小:无法利用预读策略优化程序的空间局部性。
- 数据块过大:将使得替换算法无法充分利用程序的时间局部性。
- Cache 命中时间 (): CPU 从 Cache 中成功获取数据所需的时间。
- Cache 内部的查找时间:包括地址解析、标记比较等。
- 数据传输时间:将命中数据从 Cache 传输到 CPU 寄存器所需的时间。
- Cache 缺失损失 (Miss Penalty, ): 发生 Cache 不命中时,将所需数据块从主存调入 Cache 并提供给 CPU 所需的额外时间。
- Cache 内的查找时间:用于确认不命中。
- 主存访问时间 (): 从主存中读取整个数据块到 Cache 的时间。
- 数据块传输时间:将数据块从主存传输到 Cache 的时间。
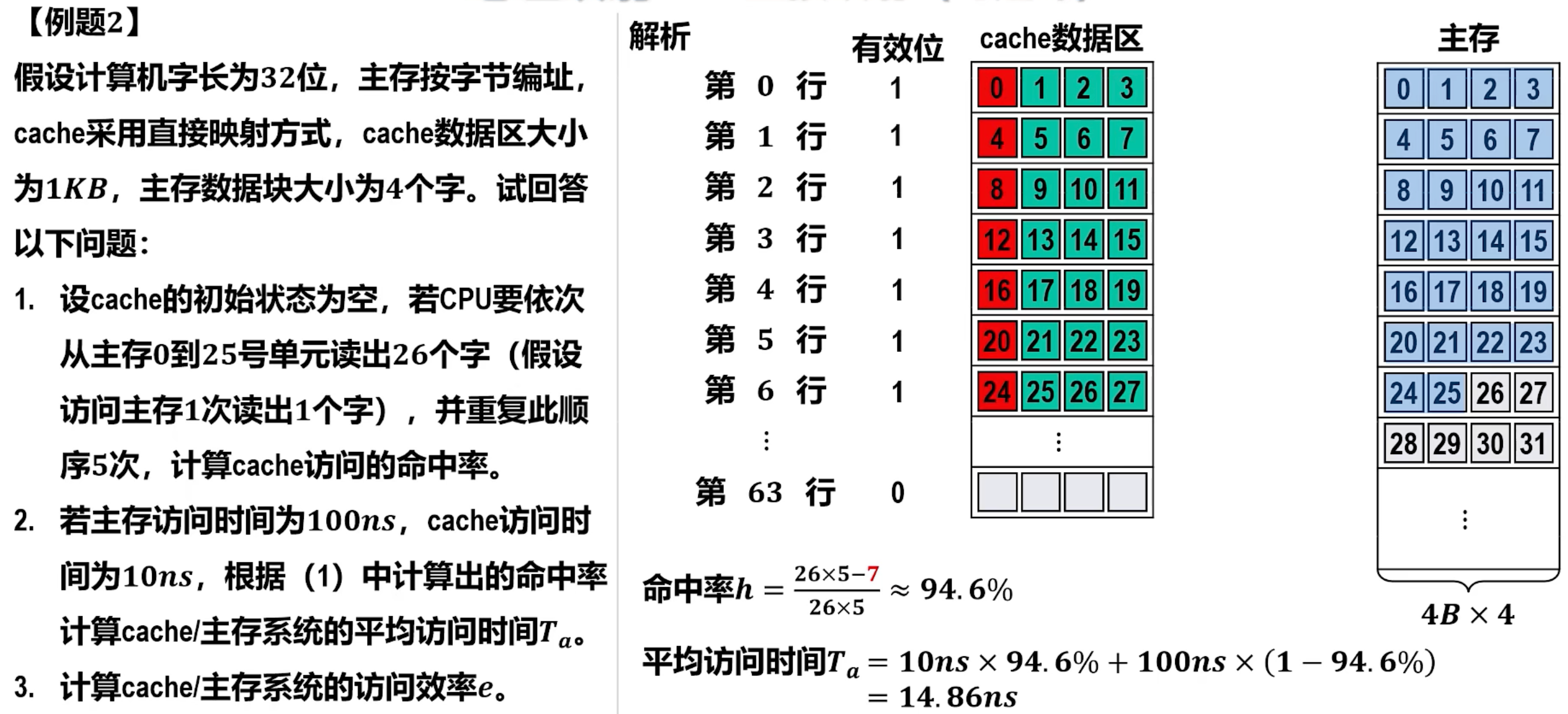
- 命中率 (Hit Rate, ): 衡量 Cache 性能的重要指标。
- 定义:CPU 访问 Cache 命中的次数占总访问次数的比例。记命中缓存次数为 ,从主存访问信息次数为 ,命中率记为
- 表达式:
- 提高命中率是 Cache 设计的关键目标,越接近 1 性能越好。
- 缺失率 (Miss Rate, ):
- 定义:CPU 访问 Cache 不命中的次数占总访问次数的比例。
- 表达式:
- 平均访存时间 (Average Memory Access Time, AMAT):
- 定义:CPU 每次访存操作在平均意义上所需的时间。这是衡量 Cache 系统整体性能的关键指标。记命中时的访问时间为 ,数据缺失情况的访问时间为 ,Cache/主存系统的平均访问时间记为
- 表达式:
- 访问效率记为
- 表达式:,其中
- 越接近 1, 越接近 1
Cache 的读、写流程
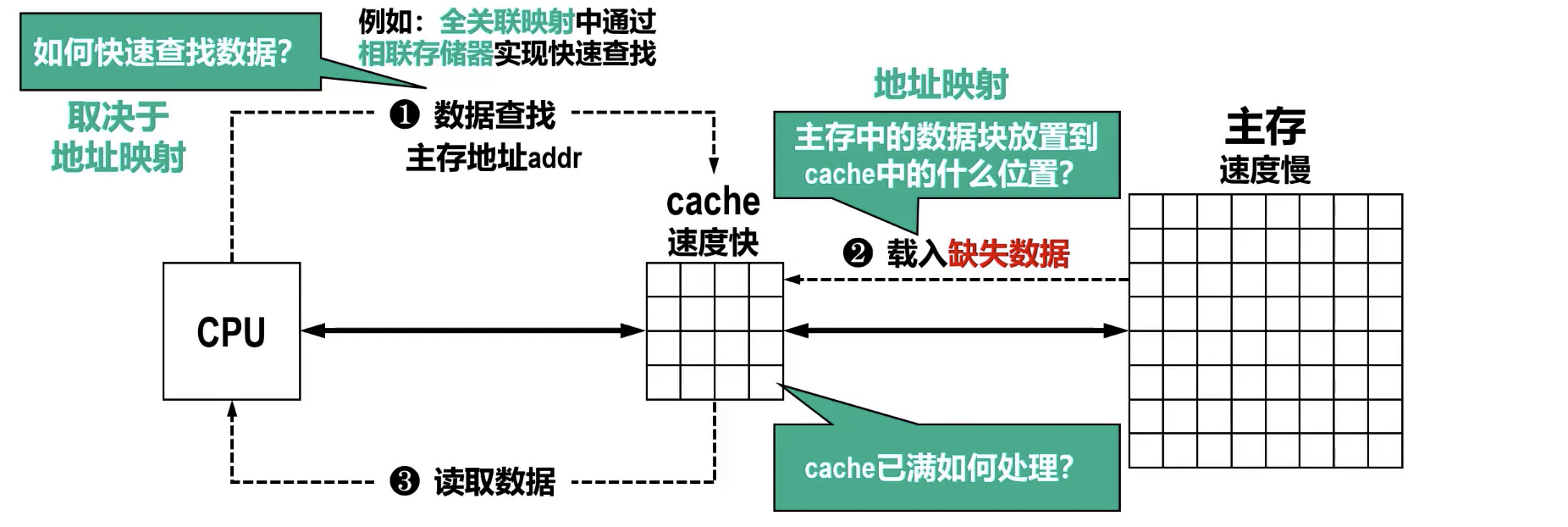
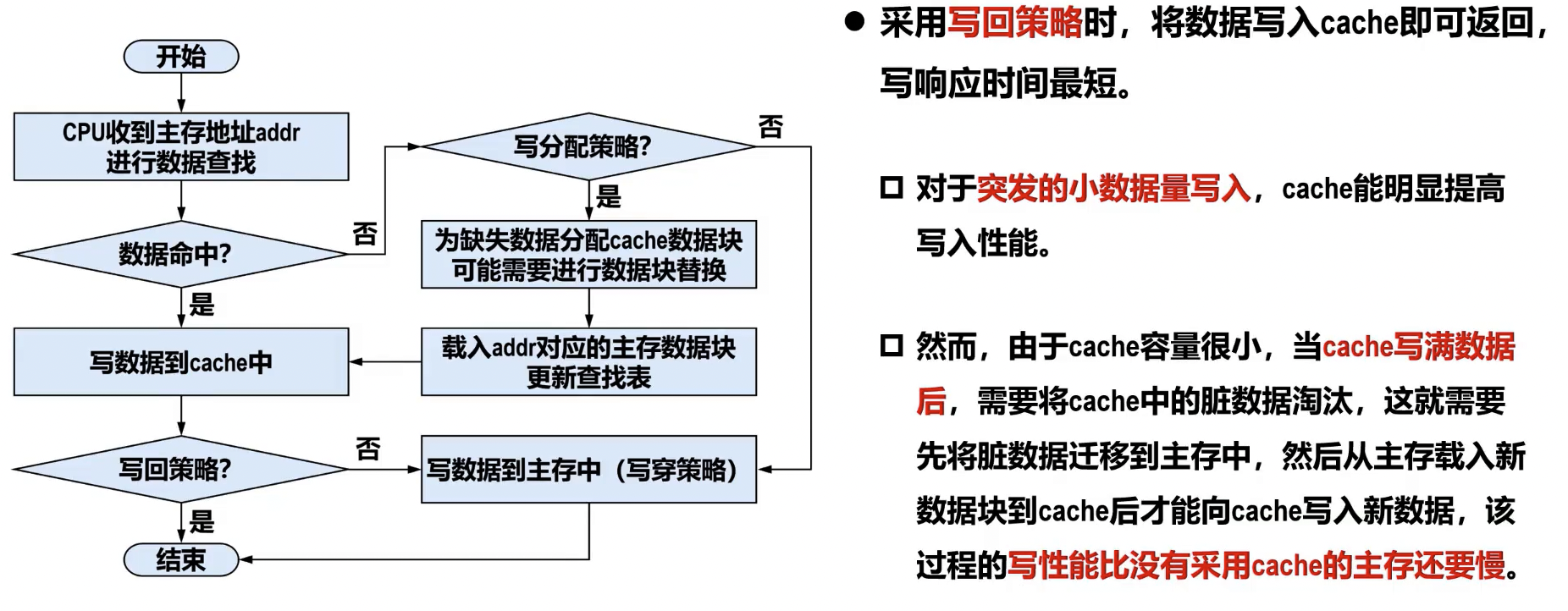
- 读流程:
- CPU 给出访存地址: CPU 发出读请求,提供要访问的内存地址。
- Cache 查找: Cache 控制器根据地址中的索引/组号定位到可能的 Cache 行,并检查该行的有效位。
- 判断命中:
- 读命中: 若有效位为 1 且 Cache 行中的标记位与主存地址的标记部分匹配,则表示数据在 Cache 中,CPU 直接从 Cache 读取数据。
- 读不命中: 若未命中,则暂停 CPU 访问,启动主存读操作,将主存中对应的整个块调入 Cache。
- 块替换 (替换策略): 若 Cache 中没有空闲块存放新调入的块,则需要根据预设的替换算法(如最近最少使用 LRU、先进先出 FIFO、随机替换等)选择一个块替换掉,再将新块调入。
- CPU 继续执行: 数据调入 Cache 后,CPU 从 Cache 读取数据并继续执行。
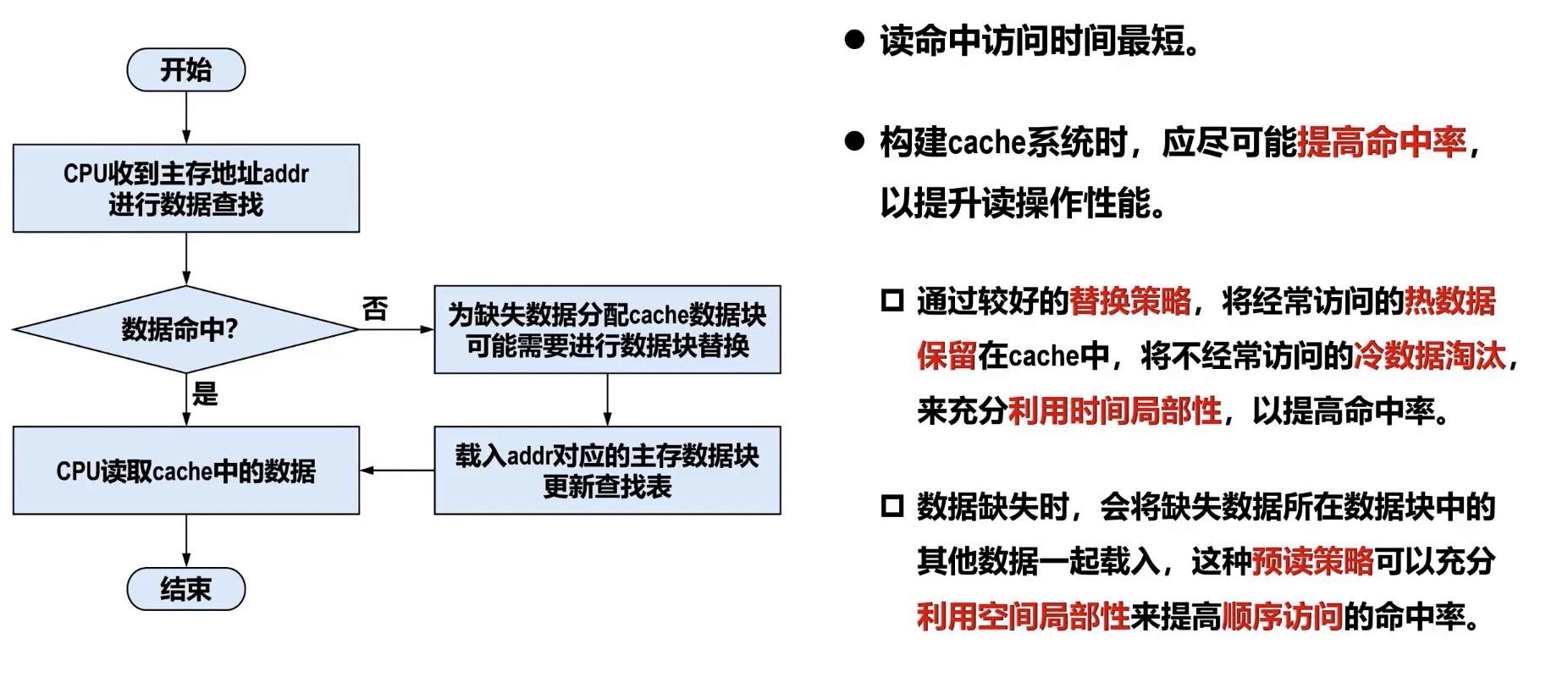
- 写流程:
- 写命中时的处理策略:
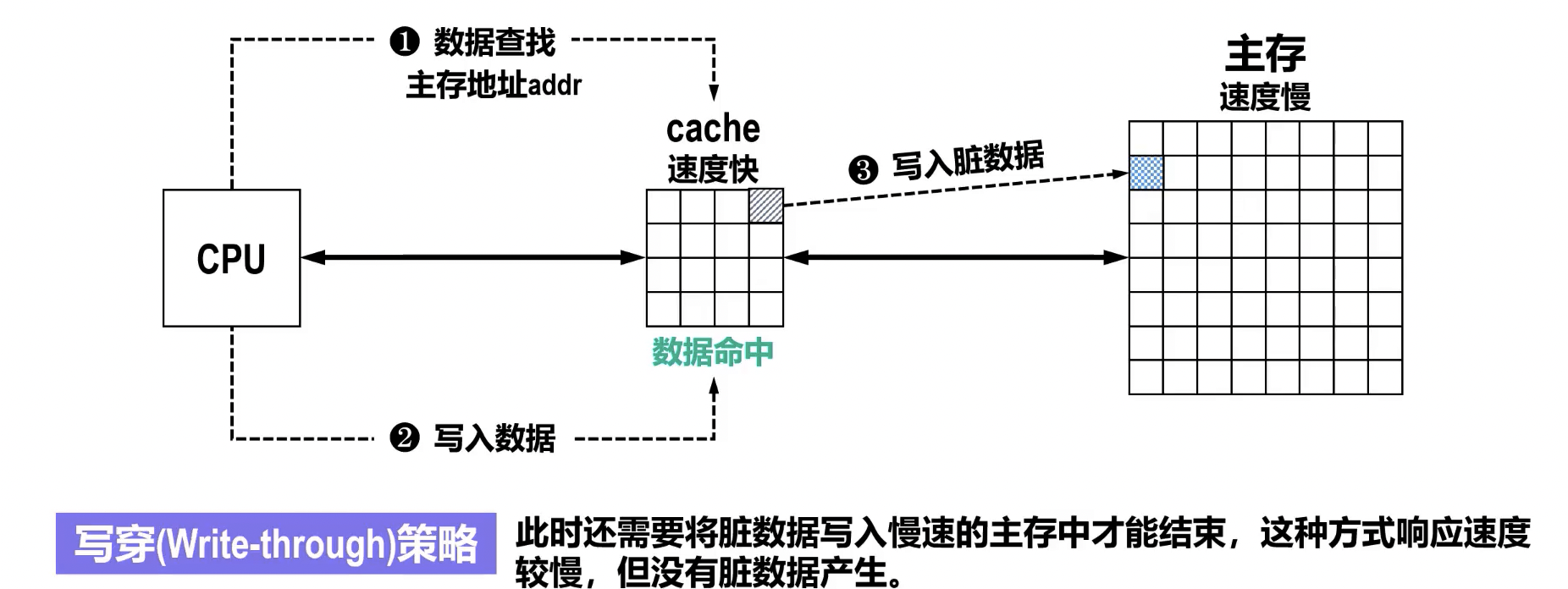
- 写直达 (写穿,Write-through):
- 特点: 数据同时写入 Cache 和主存。
- 优点: 保证 Cache 和主存数据的一致性;实现简单。
- 缺点: 每次写操作都访问主存,速度较慢,可能成为系统瓶颈。
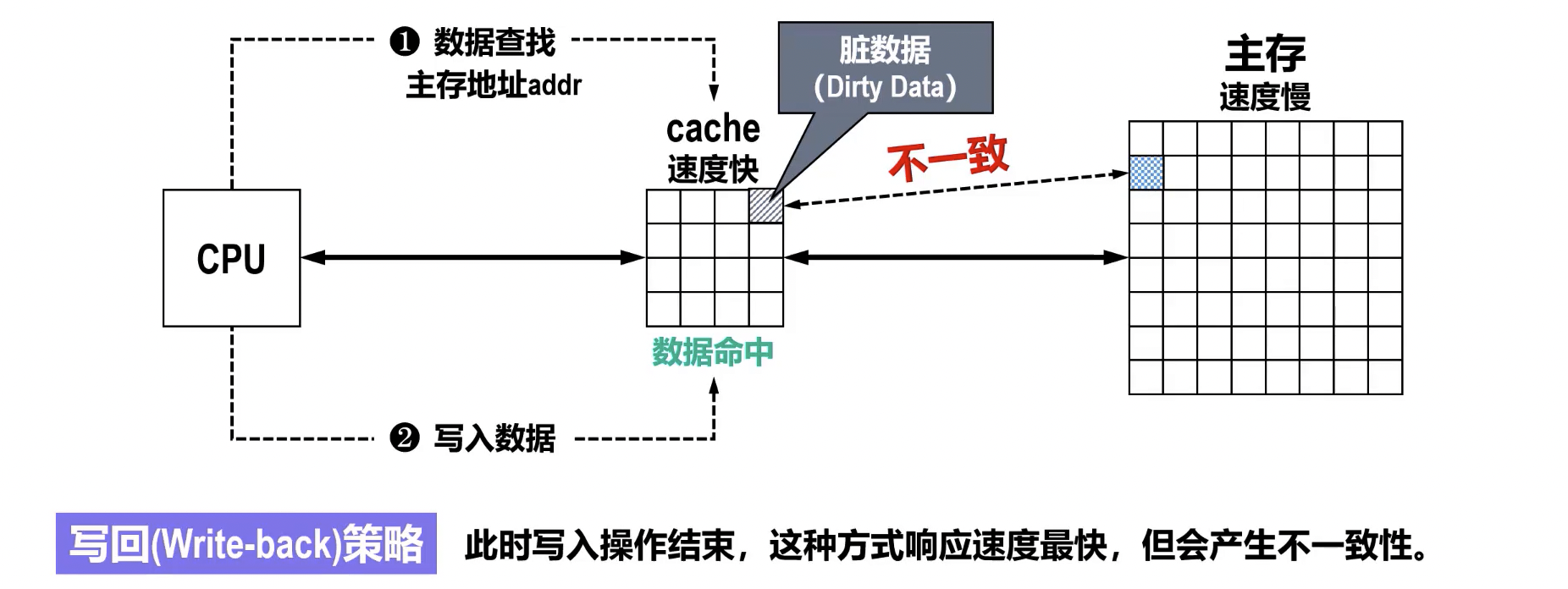
- 写回 (Write-back):
- 特点: 数据只写入 Cache,并设置 Cache 块的**脏位 (Dirty Bit)**为 1(表示该块已被修改且与主存不一致)。当该 Cache 块被替换或被其他部件访问时,若脏位为 1,才将该块写回主存。
- 优点: 写入速度快,减少访存次数。
- 缺点: Cache 和主存数据可能暂时不一致;实现相对复杂,需要维护脏位。
- 写直达 (写穿,Write-through):
- 写不命中时的处理策略:
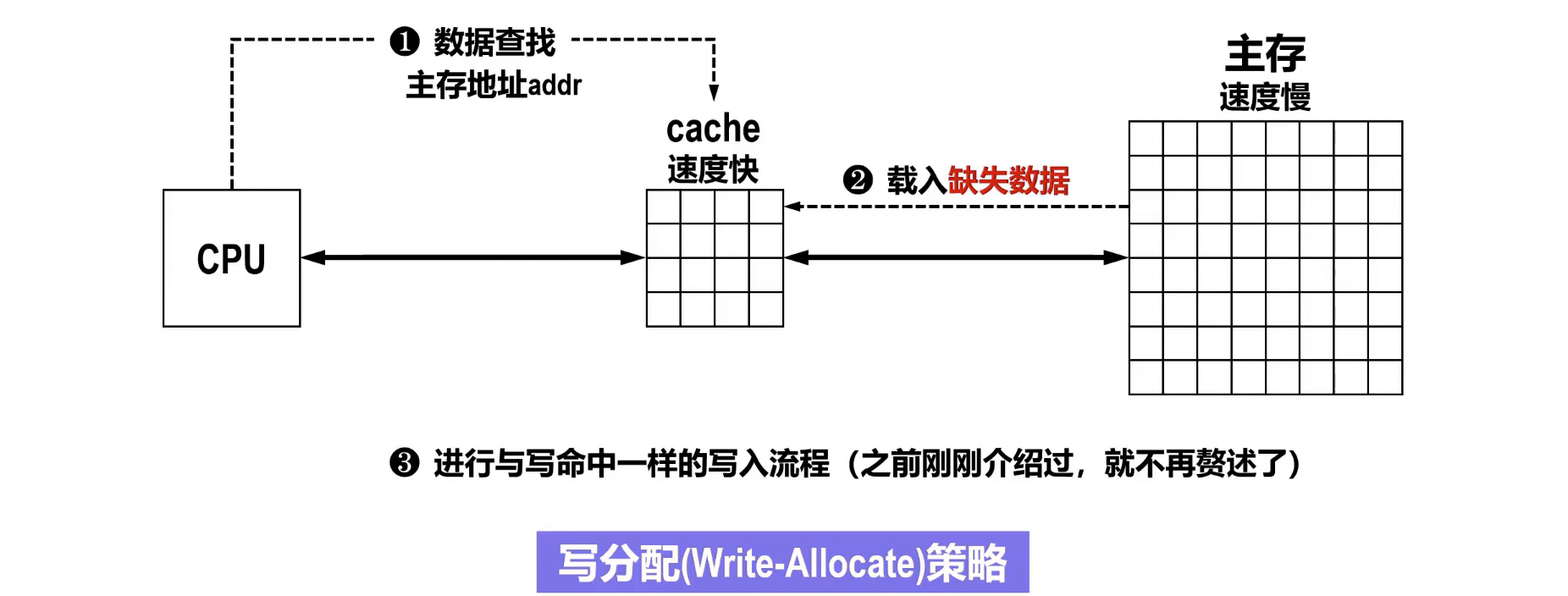
- 写分配 (Write Allocate / Fetch on Write):
- 特点: 将主存中对应的块调入 Cache,再进行写操作(类似于读不命中)。
- 适用场景: 通常与写回策略配合使用,以利用空间局部性。
- 非写分配 (No-Write Allocate):
- 特点: 数据直接写入主存,不调入 Cache。
- 适用场景: 通常与写直达策略配合使用,因为每次写操作都会更新主存,无需将块调入 Cache。
- 写分配 (Write Allocate / Fetch on Write):
- 写命中时的处理策略:
写流程总结
Cache 地址映射
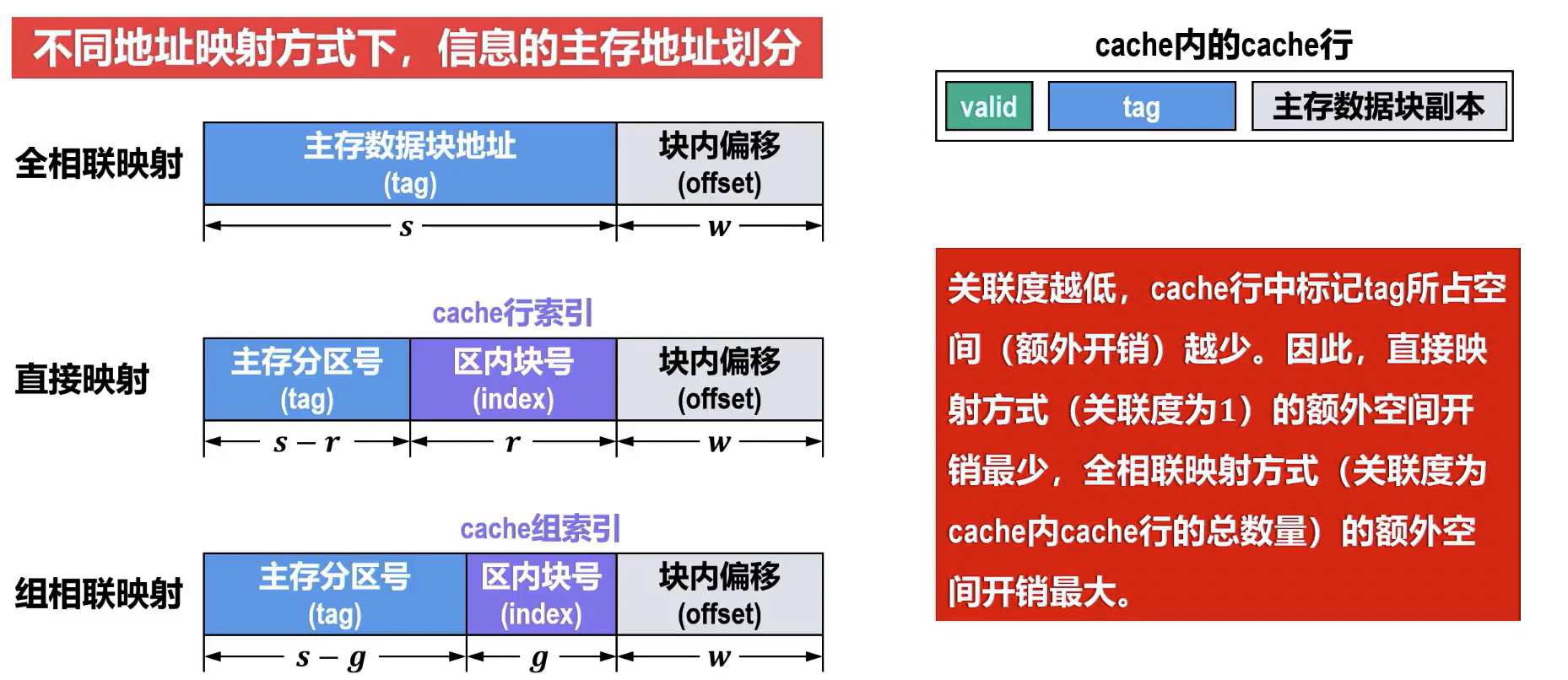
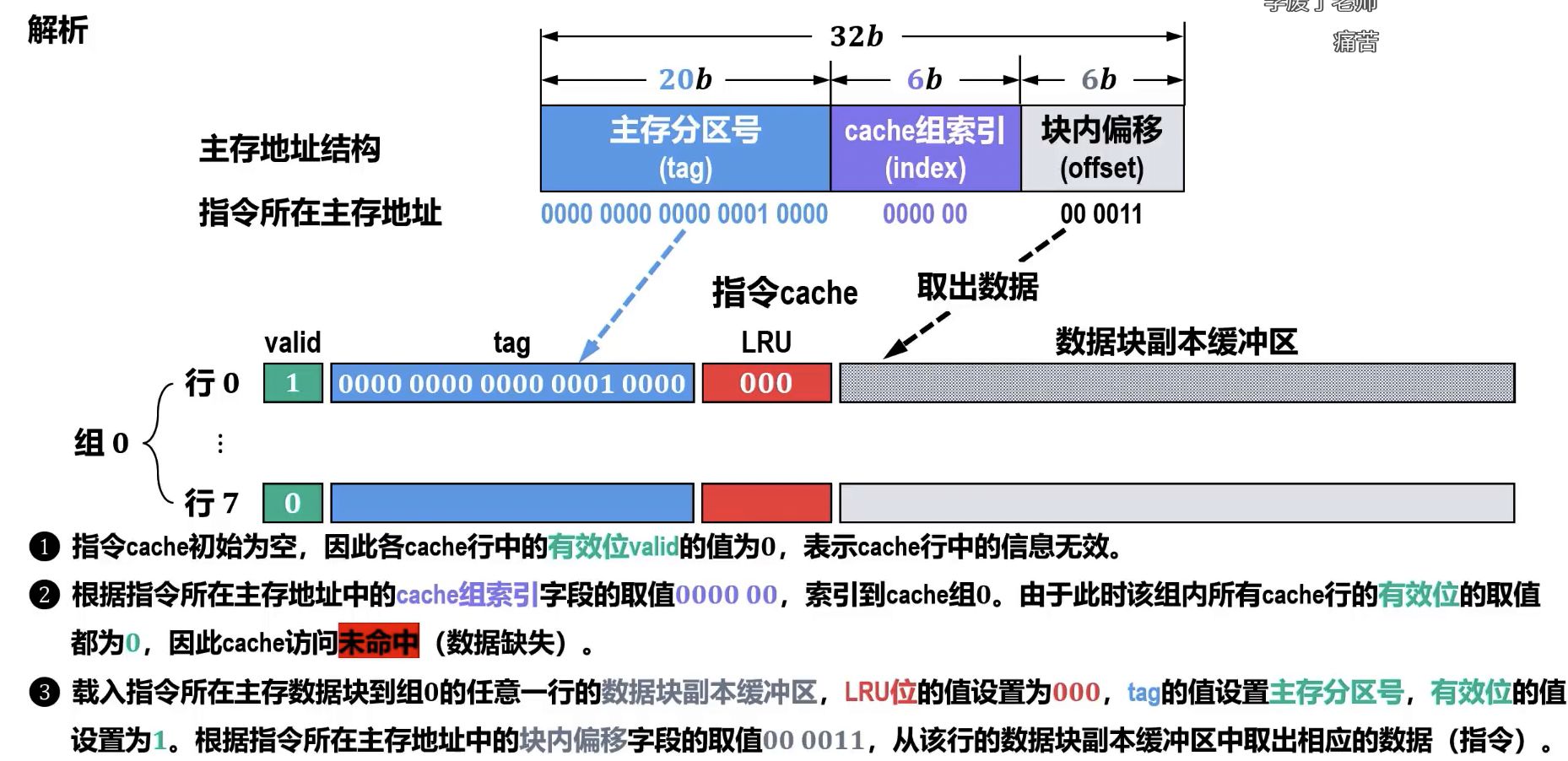
- 基本概念: 地址映射是规定主存中的块如何映射到 Cache 中的行的规则。主存地址在 Cache 访问时通常被划分为三部分:标记 (Tag)、块号/行号/组号 (Index/Set Index)、块内地址/字偏移 (Block Offset/Word Offset)。
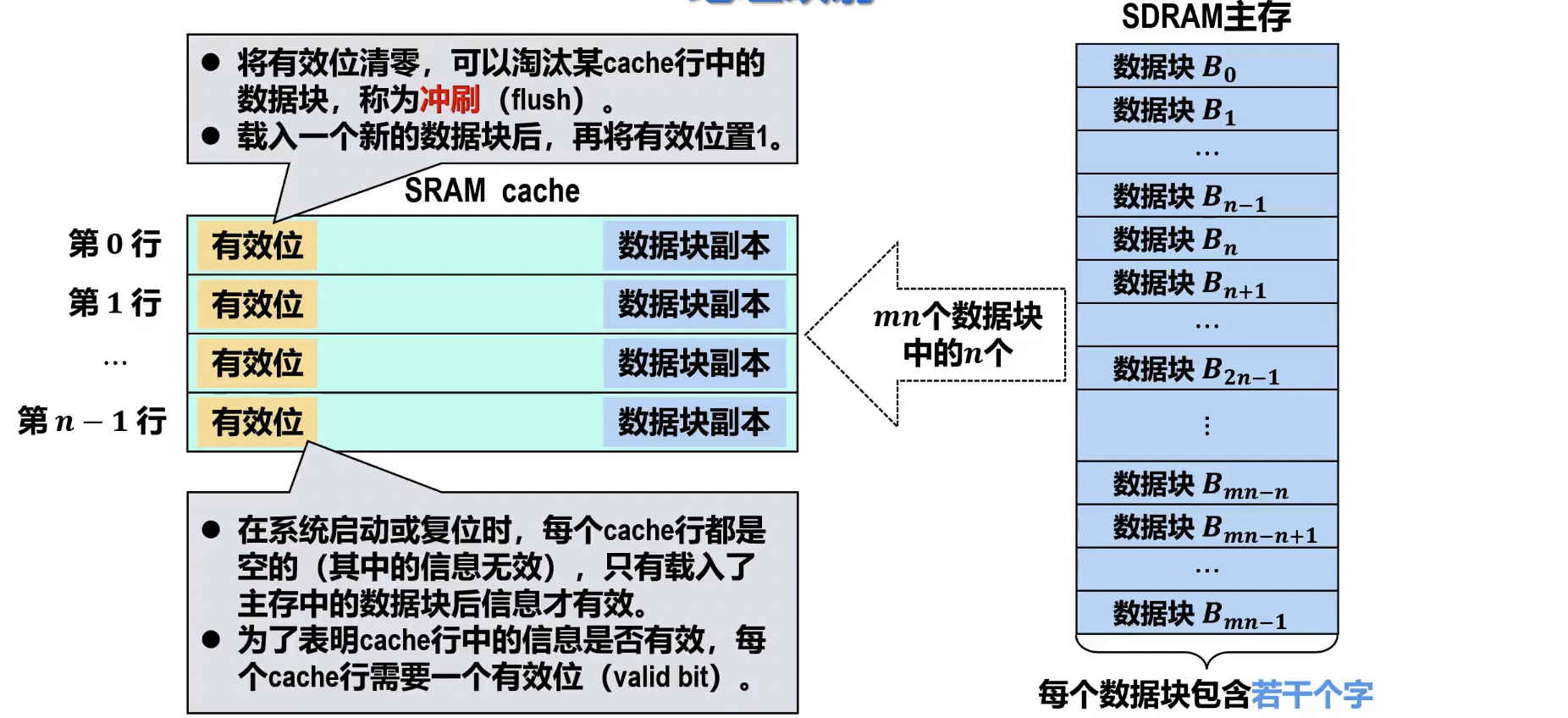
- Cache 行的数据结构
- 有效位 (Valid Bit):指示该 Cache 行中的数据是否有效(即是否载有主存中的有效数据块)。当 Cache 行被加载数据后置为 1;Cache 初始化或数据块被替换时可能置为 0。
- 数据块副本 (Data Block Copy):存储从主存中复制过来的实际数据块。其大小即为 Cache 块(或行)的大小,例如 32B、64B 等。
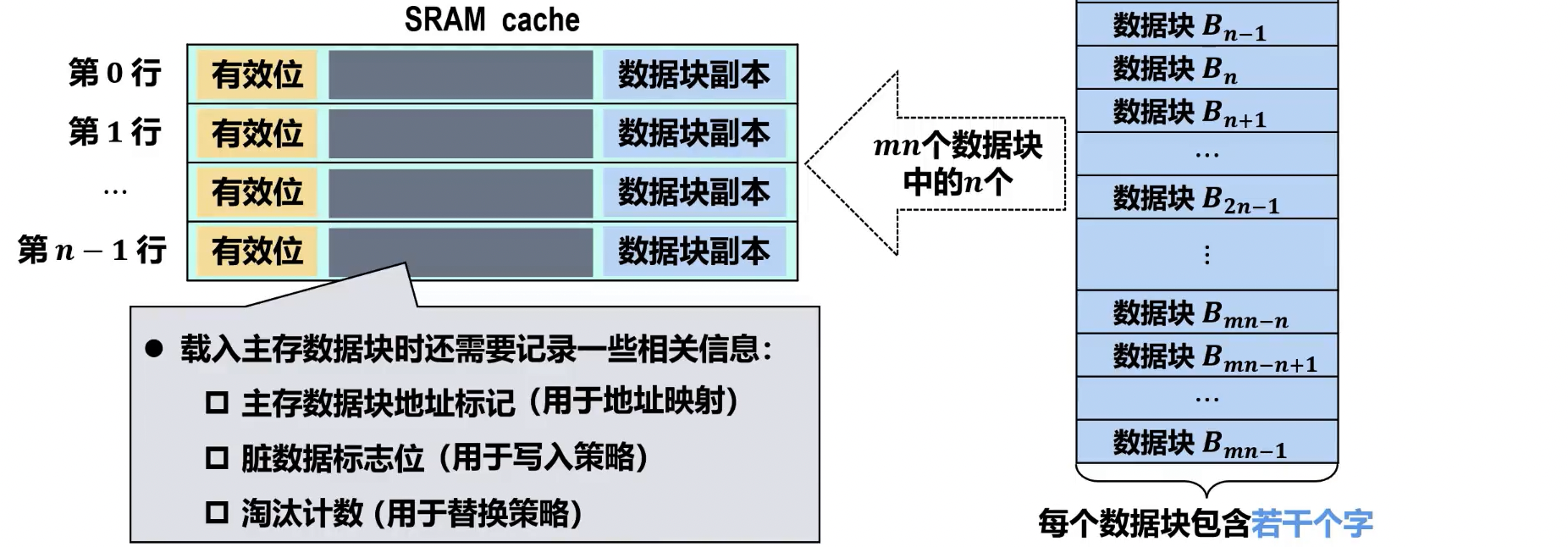
- 主存数据块相关信息
- 准存数据块地址标记 (Tag):用于在地址映射时,标识当前 Cache 行存储的是主存中哪个数据块。CPU 访问主存地址时,将地址的标记位与 Cache 行中存储的标记进行比较,以判断是否命中。
- 脏数据标志位 (Dirty Bit):指示该 Cache 行中的数据是否已被修改(即与主存中的对应数据块不一致)。主要用于写回法写入策略,当脏数据标志位为 1 时,在 Cache 行被替换前必须将修改后的数据写回主存。
- 淘汰计数(Replacement Counter):用于 Cache 替换策略,记录 Cache 行的使用情况或访问频率,以便在发生 Cache 冲突时,选择被替换的 Cache 行。常见的有:近期最少使用 (LRU) 计数、先进先出 (FIFO) 计数等。
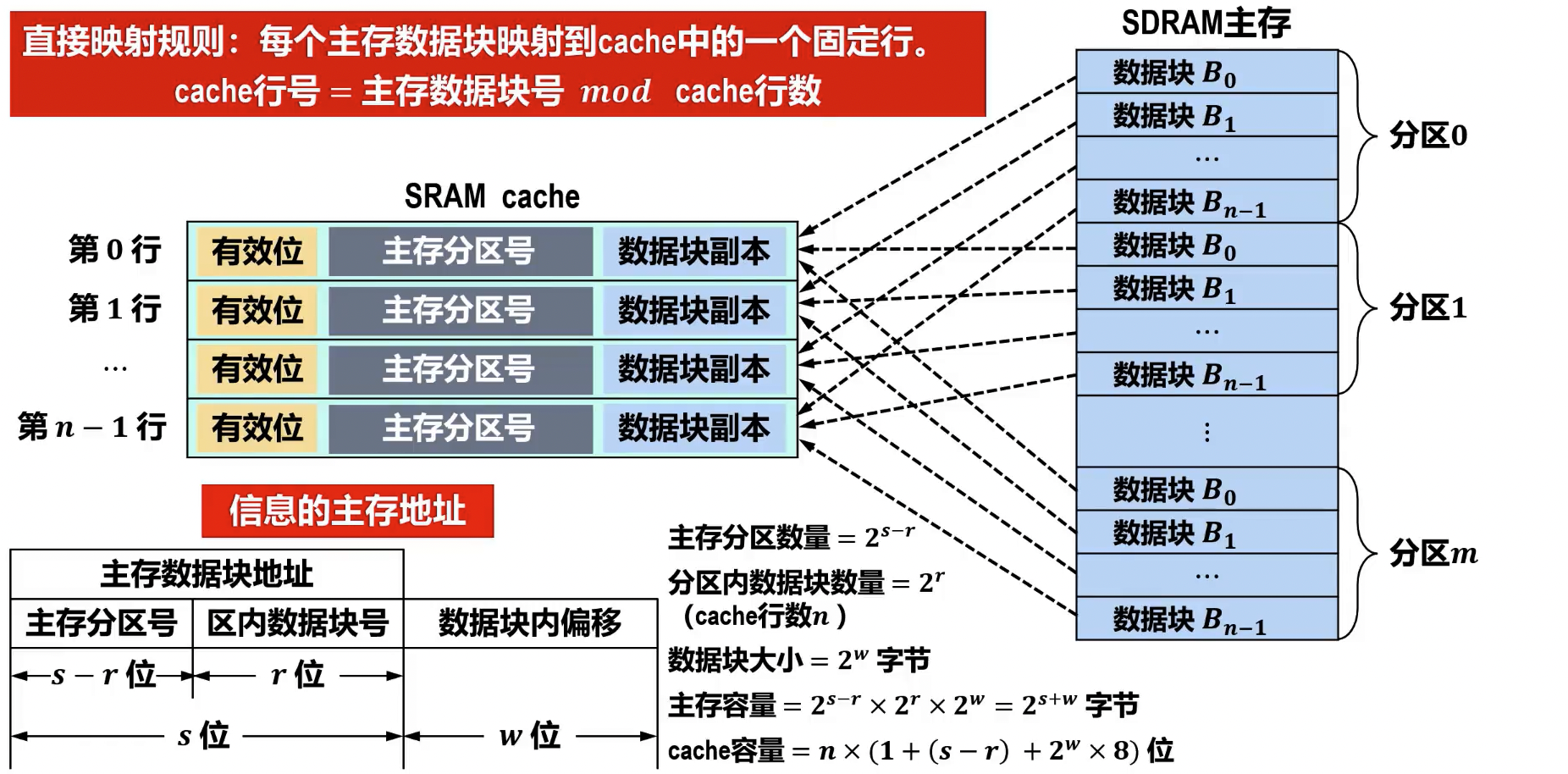
直接映射(Direct Mapping)
- 原理: 主存中的每个块只能映射到 Cache 中的唯一特定行。
- 映射关系通常为:**Cache 行号 = 主存块号 % Cache 总行数 **。
- 地址结构:
主存地址 = | 标记 | Cache 行号 (Index) | 块内地址 (Offset) |
- 标记: 用于标识当前 Cache 行存储的是哪个主存块的数据。
- Cache 行号: 用于直接定位 Cache 中的某一特定行。
- 块内地址: 用于在 Cache 行中定位具体的字。
- 优点:
- 实现简单,硬件开销小。
- 查找速度快,因为只需根据 Cache 行号直接定位并比较一个特定的 Cache 行。
- 缺点:
- 灵活性差,Cache 利用率低。
- 容易发生冲突不命中 (Conflict Miss),即使 Cache 未满,如果多个主存块竞争同一 Cache 行,也会导致频繁替换。
- 查找过程: CPU 给出主存地址,根据地址中的“Cache 行号”部分直接定位到 Cache 中的对应行。然后,比较该行的“标记”与主存地址中的“标记”是否一致,并检查有效位。
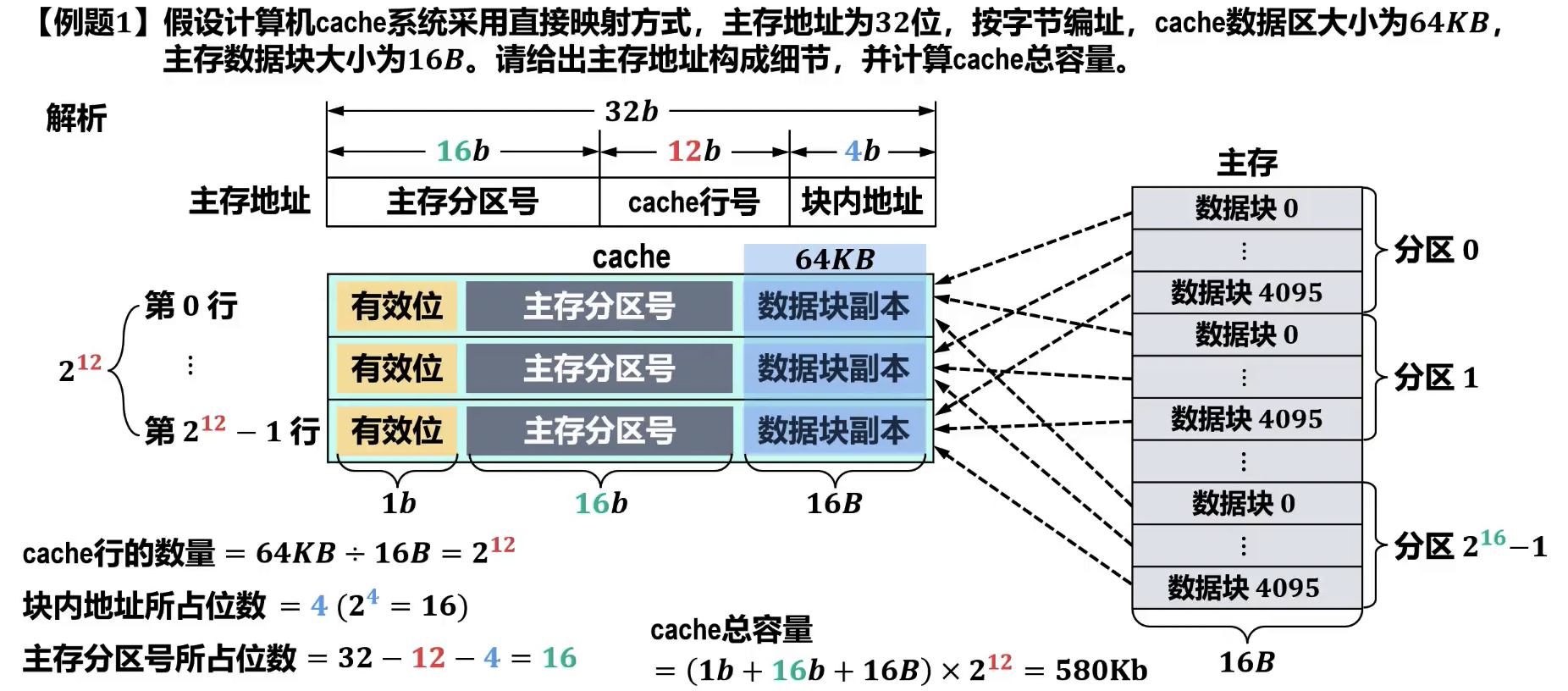
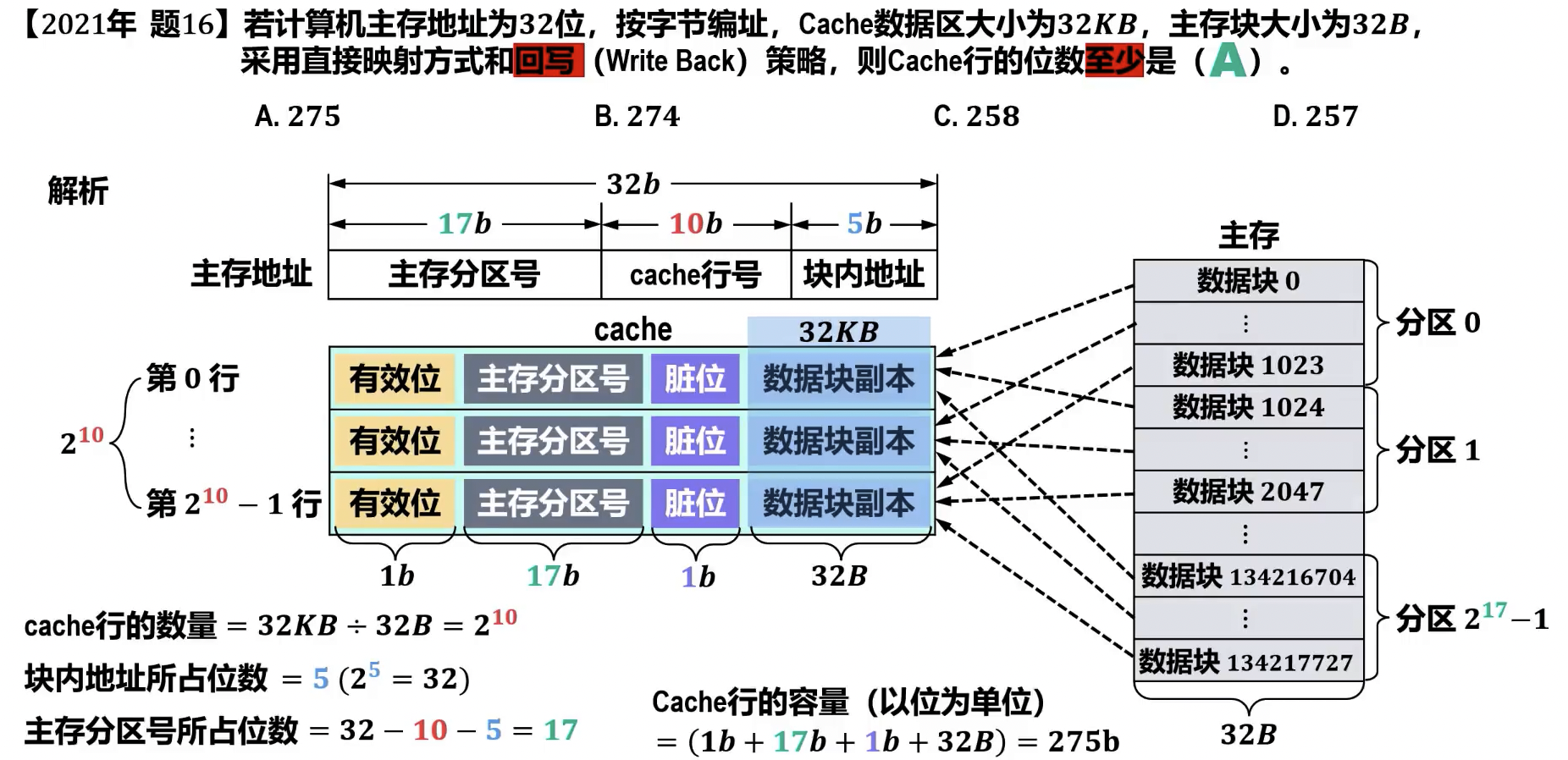
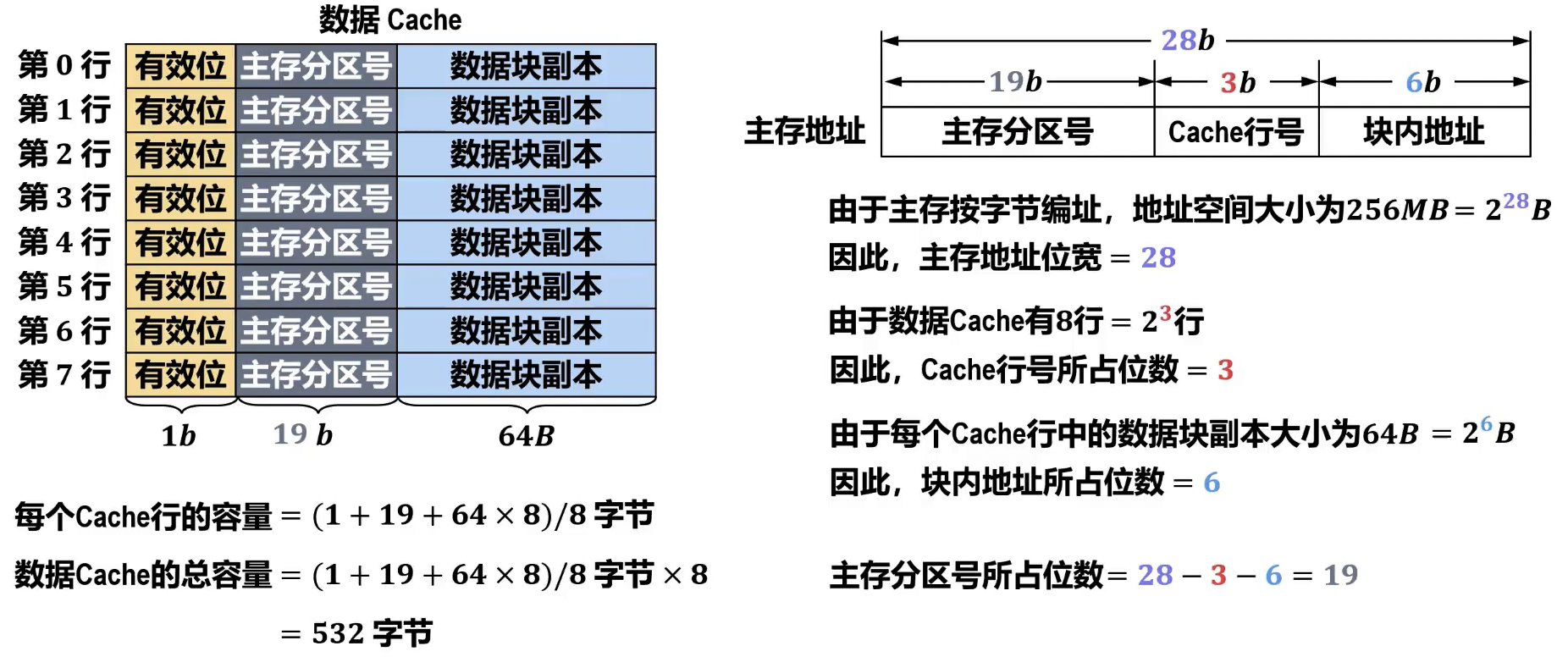
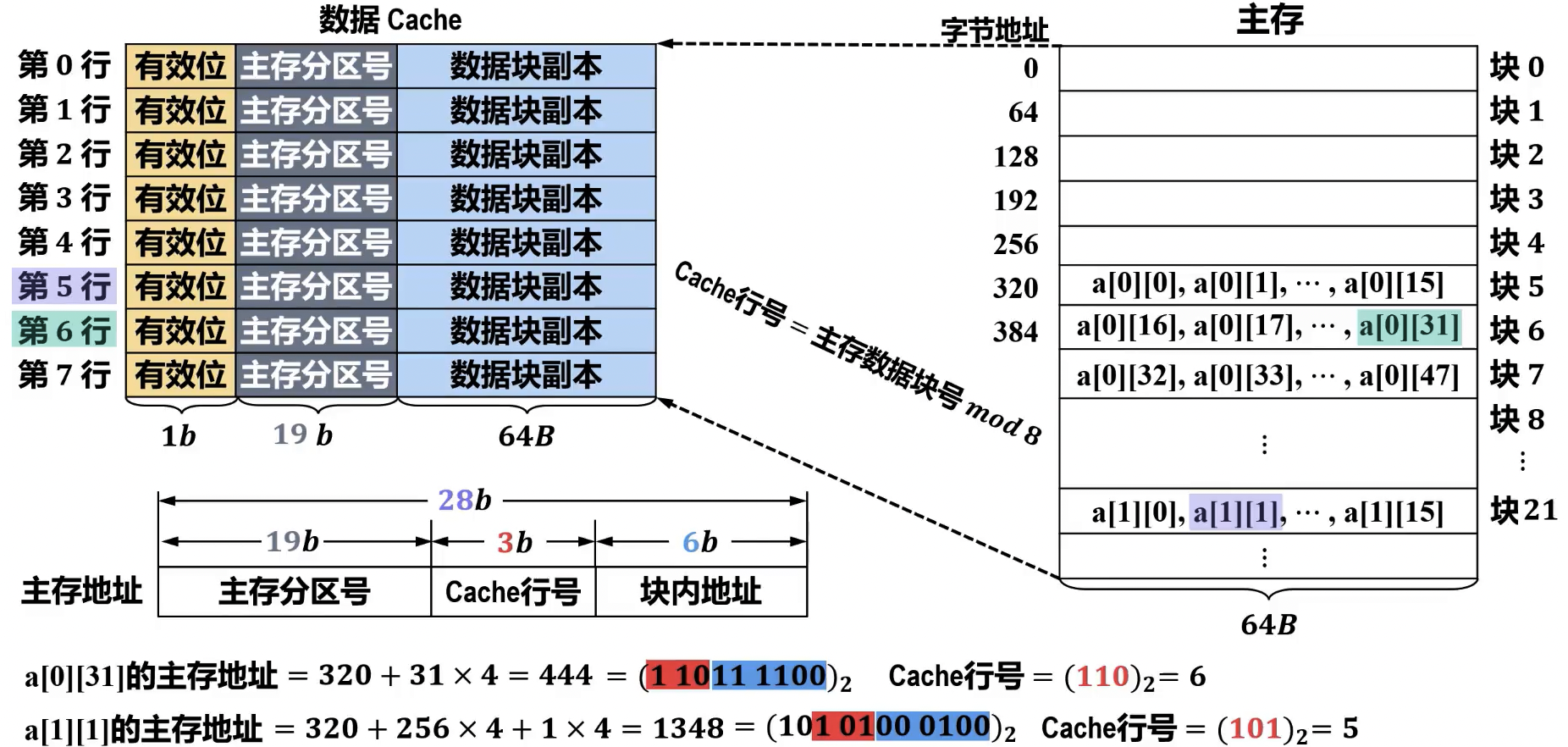
- 计算
- 主存分区数量 =
- 分区内数据块数量 (Cache 行数 ) =
- 数据块大小 = 字节
- 主存容量 = 字节
- Cache 容量 (总位数) = 位,其中 为主存分区号(tag)
硬件逻辑实现
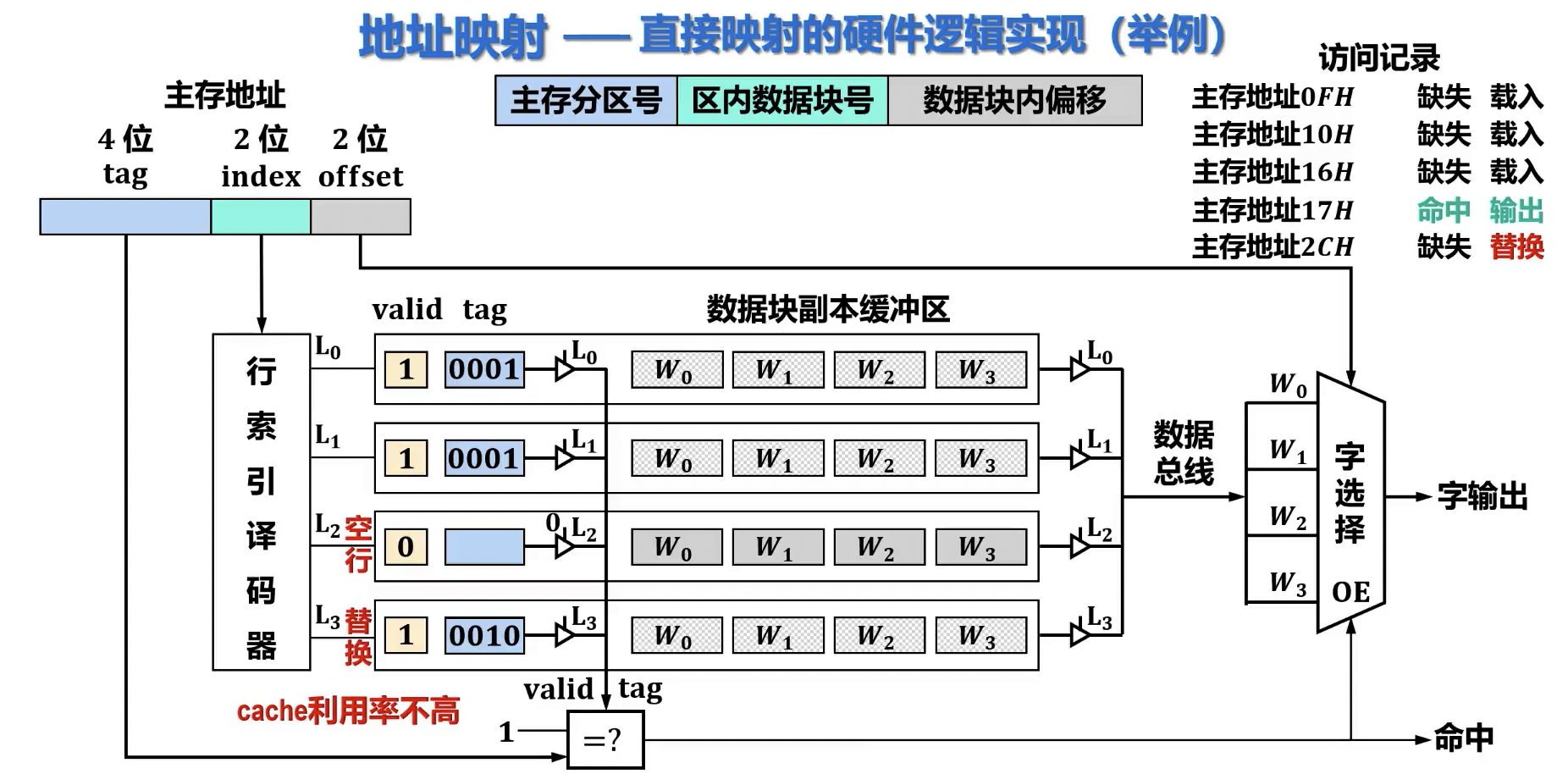
- 实现成本低(仅需要译码器和一个比较器)
习题




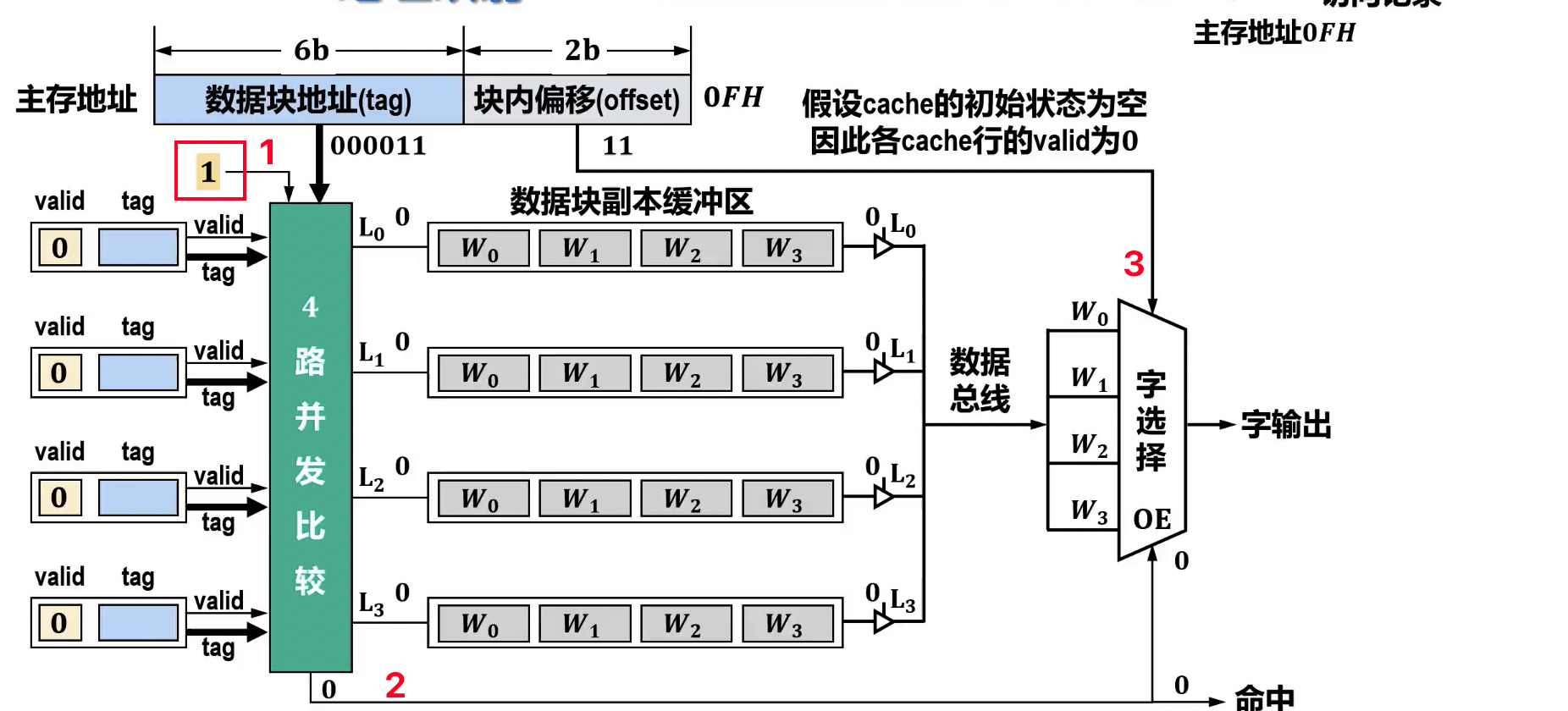
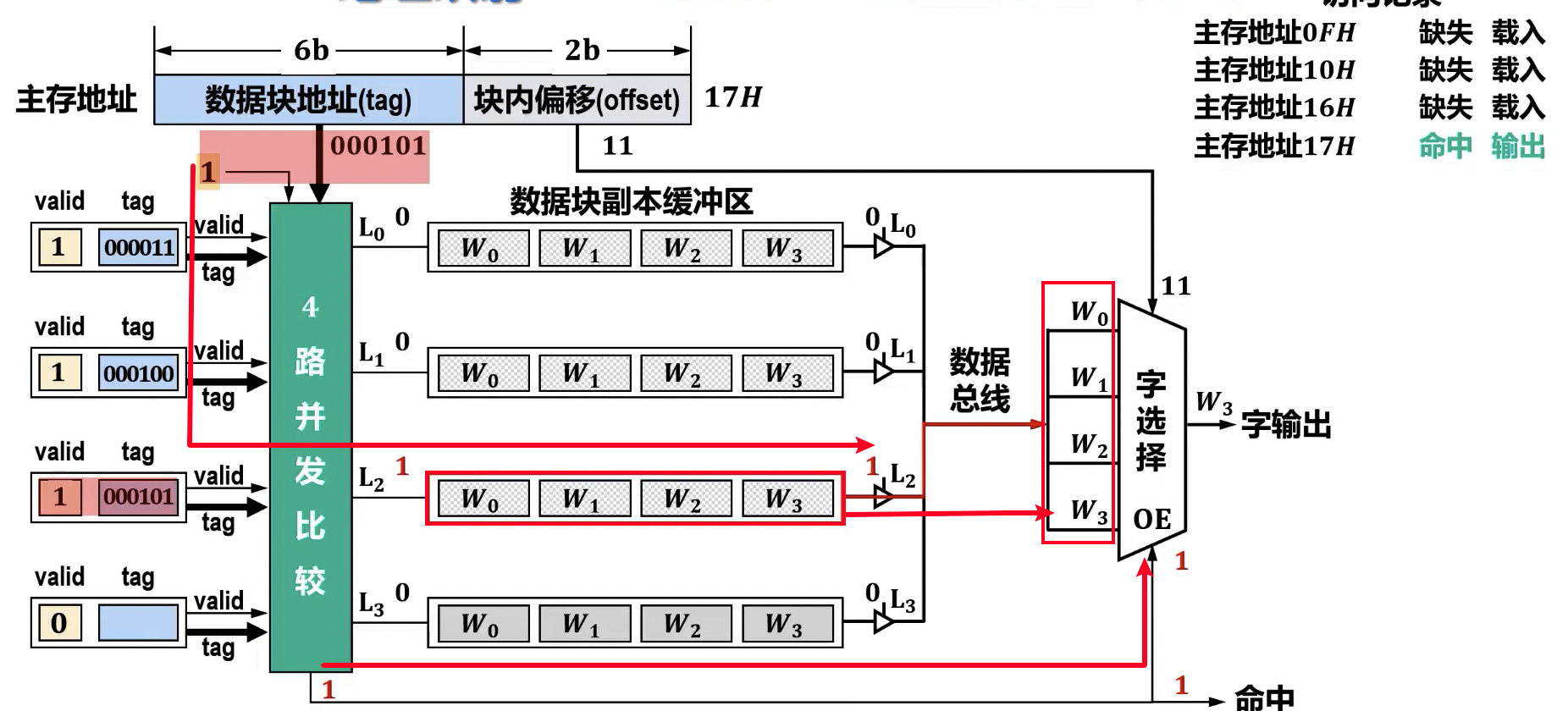
全相联映射(Full Associative Mapping)
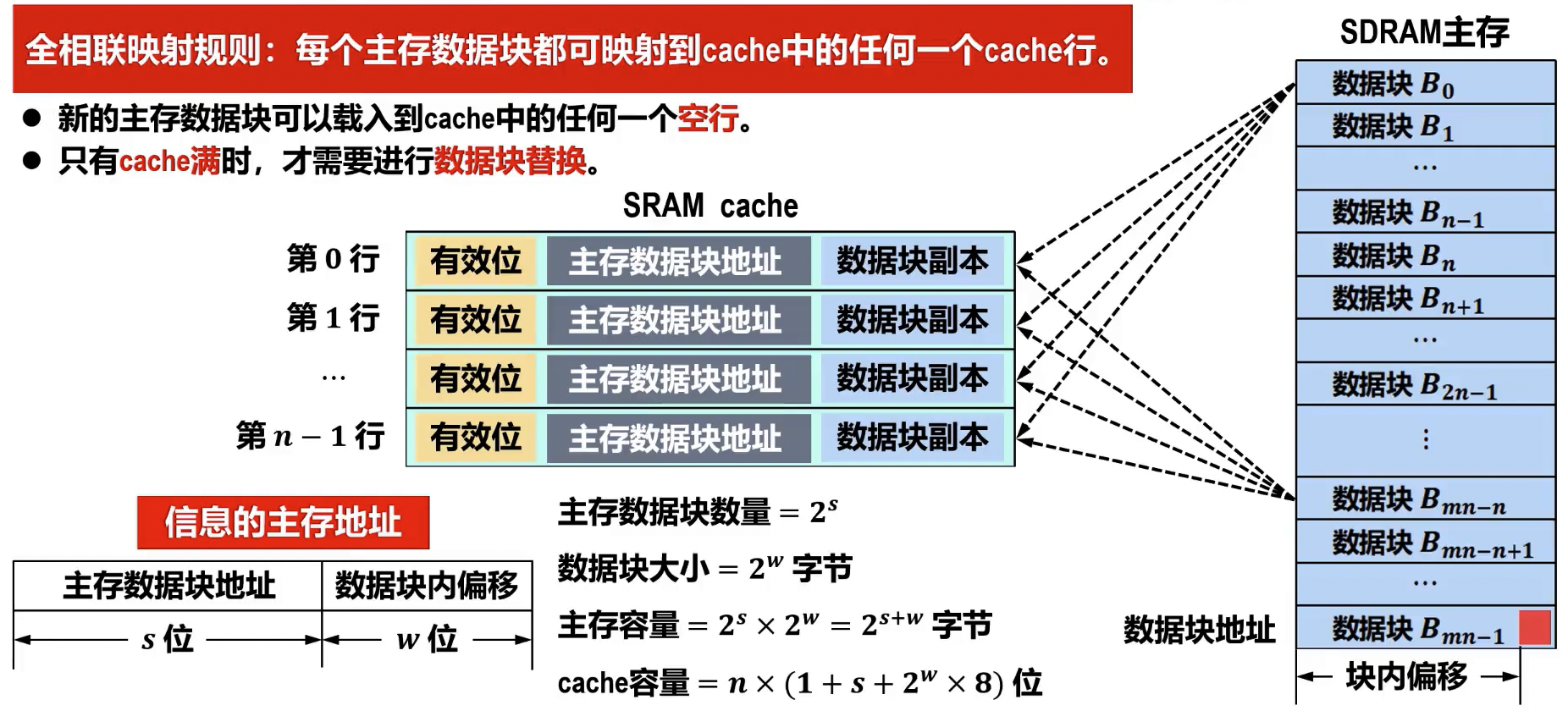
- 原理: 主存中的每个块可以映射到 Cache 中的任意空闲行。
- 地址结构:
主存地址 = | 数据块地址 (Tag) | 块内地址 (Offset) |
- 数据块地址: 用于标识当前 Cache 行存储的是哪个主存块的数据。
- 块内地址: 用于在 Cache 行中定位具体的字。
- 优点:
- Cache 利用率高,冲突率低,因为块可以存放在任何空闲位置。
- 只有 cache 满时,才进行数据块替换。
- 冲突不命中率最低,能最大限度地利用 Cache 空间。
- Cache 利用率高,冲突率低,因为块可以存放在任何空闲位置。
- 缺点:
- 实现复杂,硬件开销大(需要并行比较所有 Cache 行的标记),只适合小容量 cache 使用。
- 查找速度相对较慢,需要复杂的查找电路(如内容寻址存储器(相联存储器) CAM)。
- 查找过程: CPU 给出主存地址,将地址中的
Tag与 Cache 中所有行的Tag进行并行比较。若有匹配且有效位为 1,则命中。 - 计算
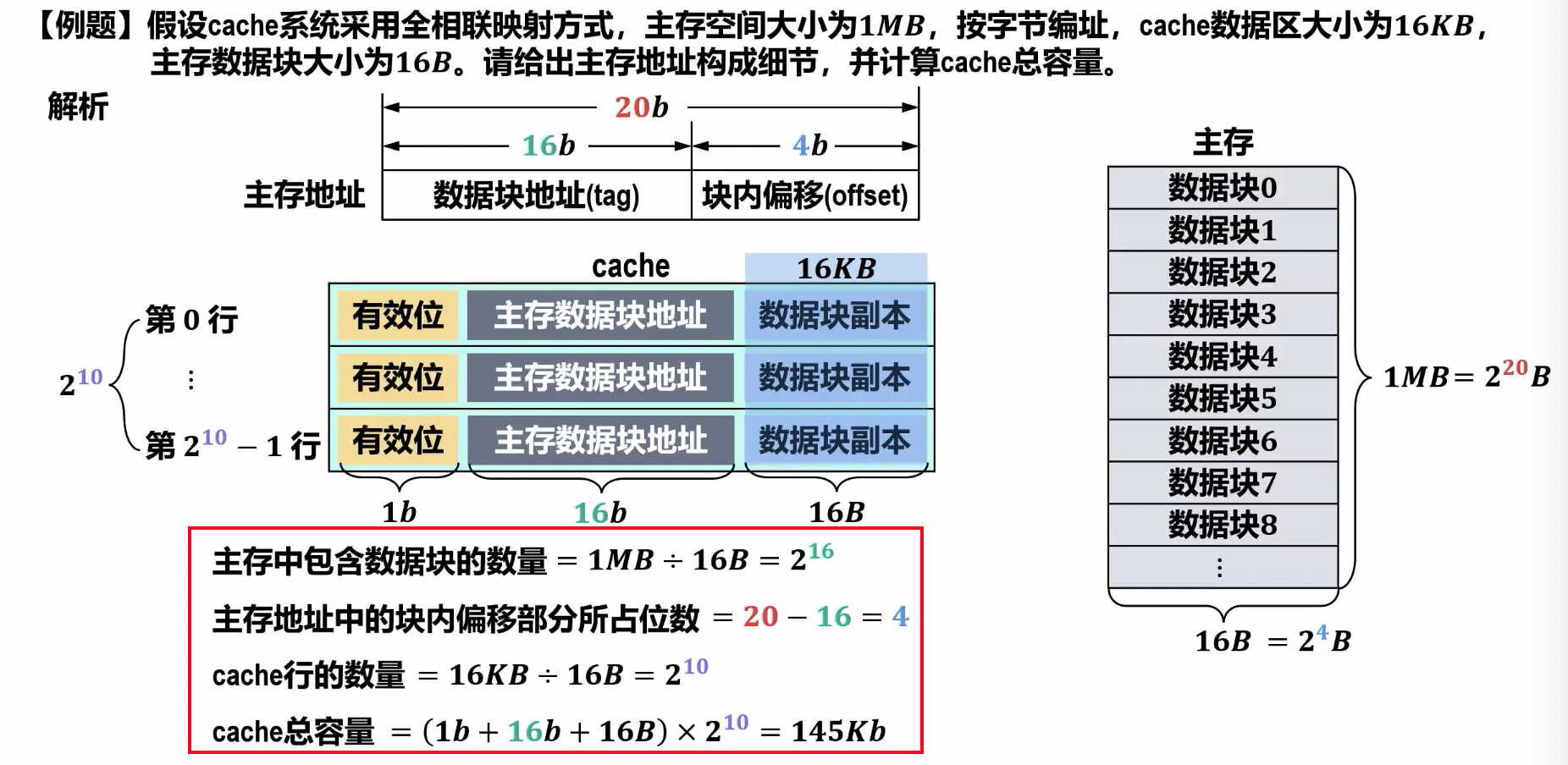
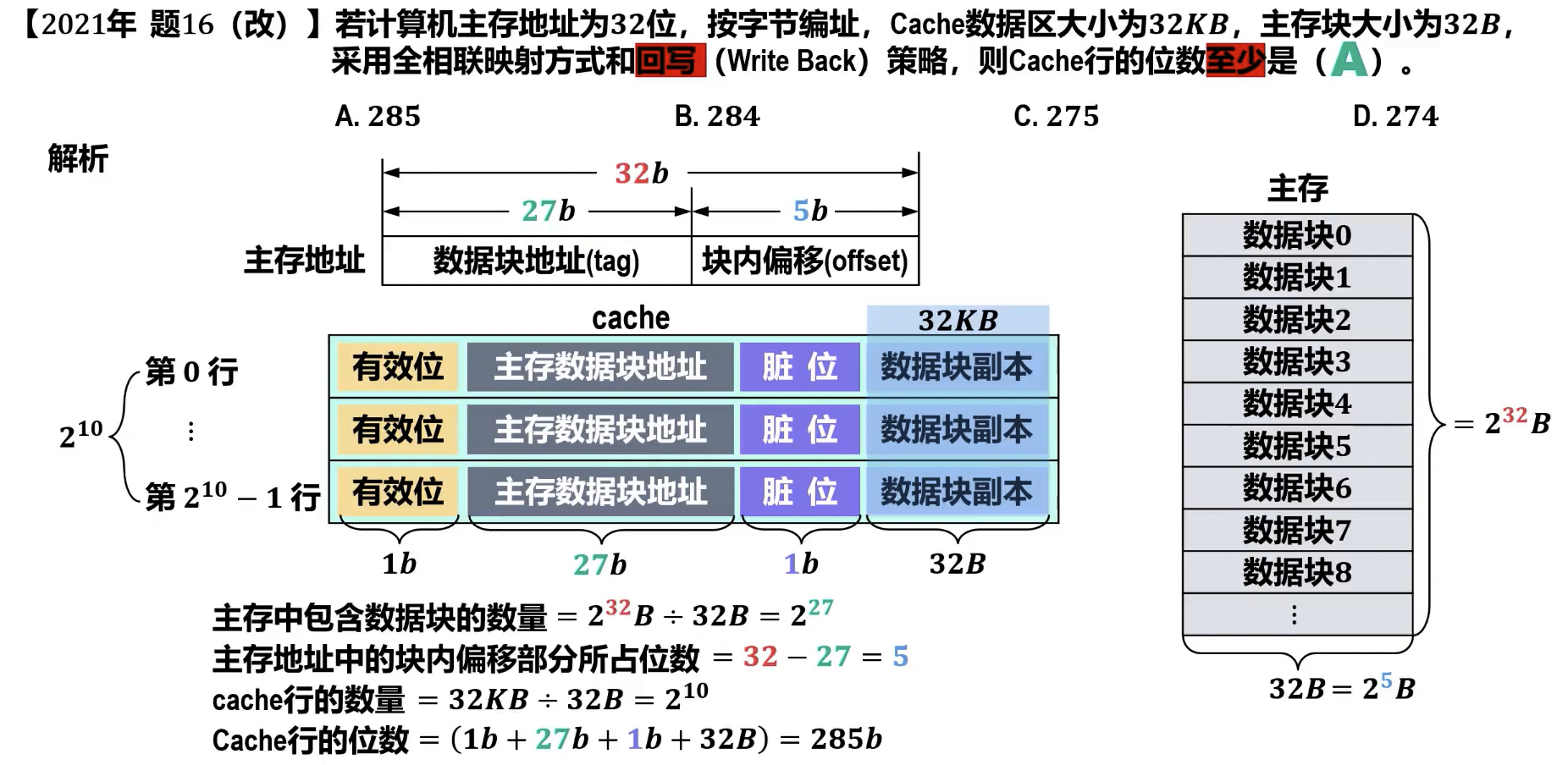
- 主存数据块数量
- 数据块大小 字节
- 主存容量 字节
- cache 容量 位
硬件逻辑实现
例题
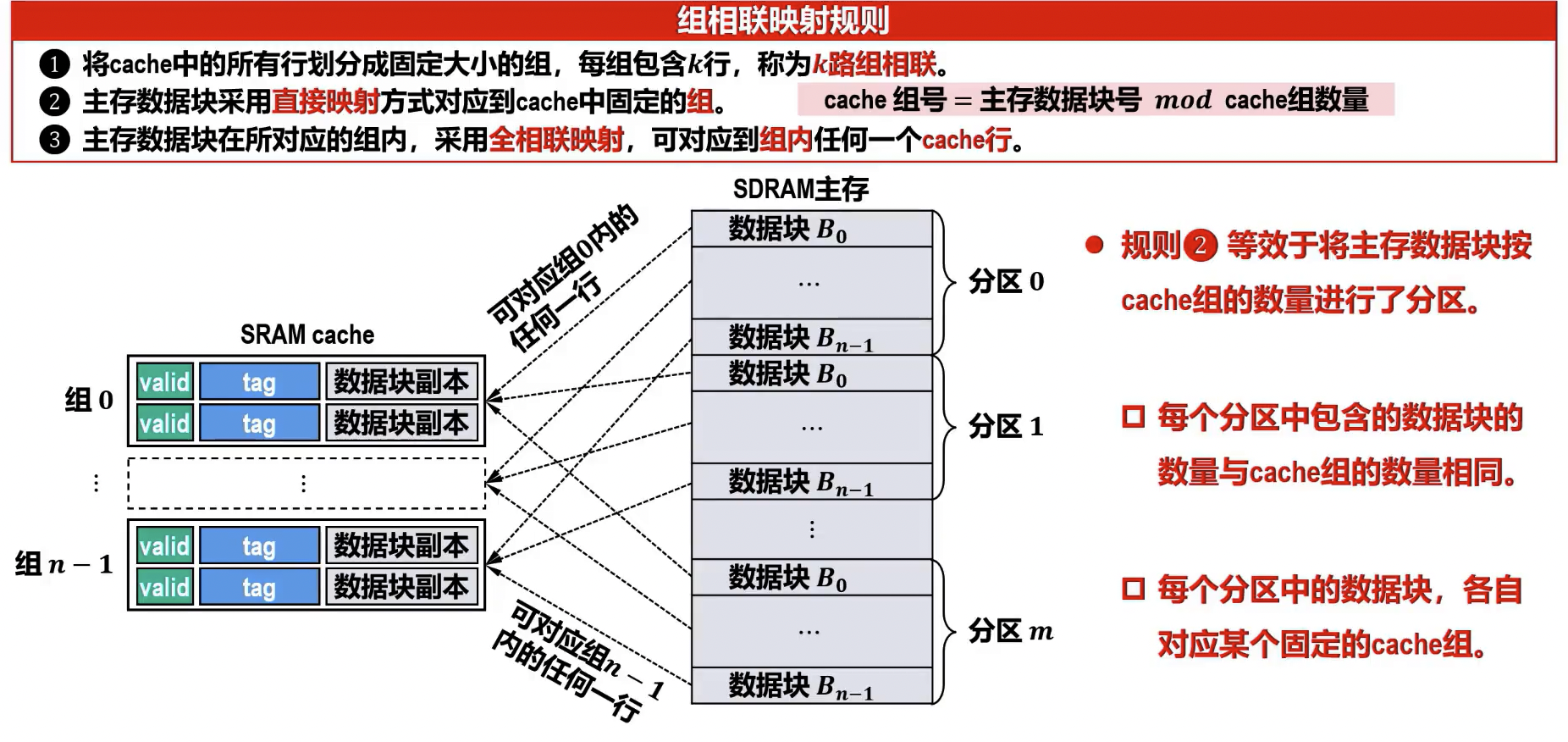
组相联映射(Set Associative Mapping)
- 原理: 综合了直接映射和全相联映射的优点。将 Cache 分为若干组,每组内采用全相联映射,组间采用直接映射。主存块首先根据其组号映射到 Cache 的某个组,然后在该组内可以映射到任意空闲行。
- 映射关系通常为:Cache 组号 = 主存块号 % Cache 总组数 。
- 但部分教材如《深入理解计算机系统》可能是Cache 组号 = 主存块号 % Cache 总行数,通常以前者为准。
- 映射关系通常为:Cache 组号 = 主存块号 % Cache 总组数 。
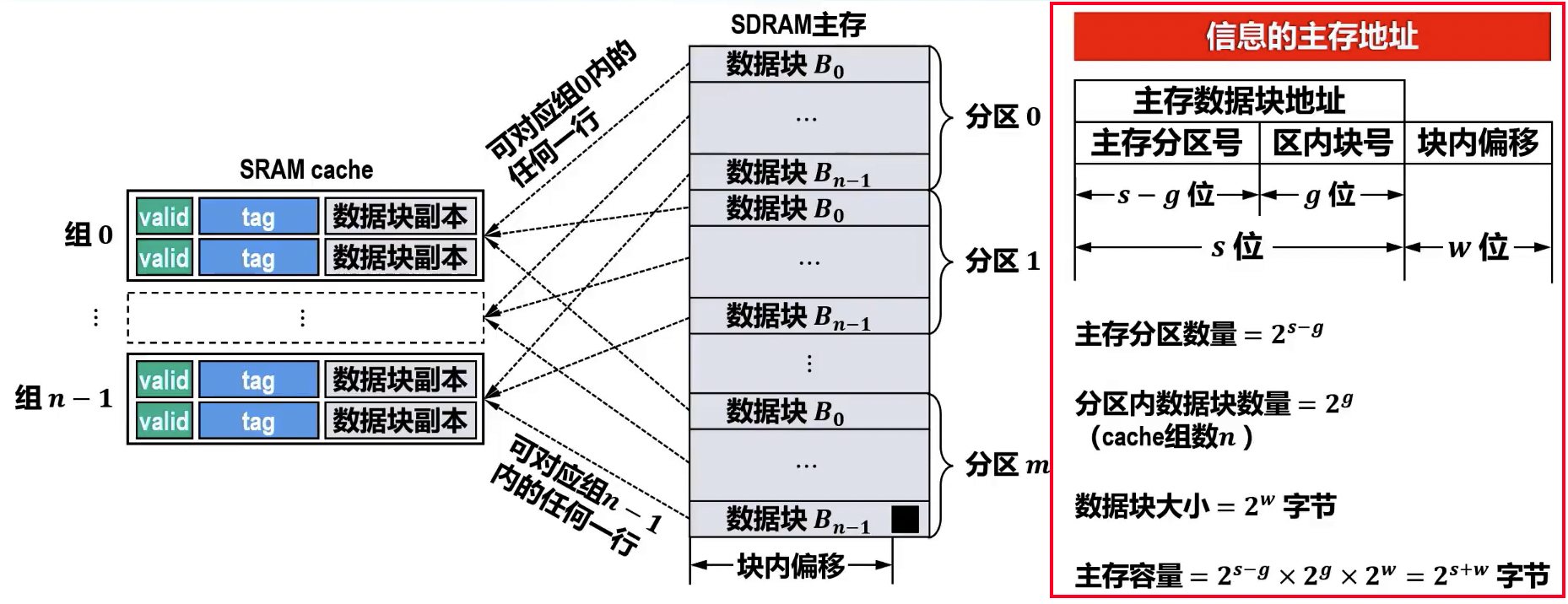
- 地址结构:
主存地址 = | 数据块地址 (Tag) | 组号 (Set Index) | 块内地址 (Offset) |
- 数据块地址: 用于标识当前组内某个 Cache 行存储的是哪个主存块的数据。
- 组号: 用于直接定位到 Cache 中的某一特定组。
- 块内地址: 用于在 Cache 行中定位具体的字。
- 优点:
- 兼顾了直接映射的简单性和全相联映射的灵活性。
- 冲突不命中率低于直接映射,高于全相联映射。
- 硬件开销和查找速度介于两者之间,是实际系统中常用的映射方式。
- 缺点:
- 实现比直接映射复杂。
- 冲突不命中率高于全相联映射。
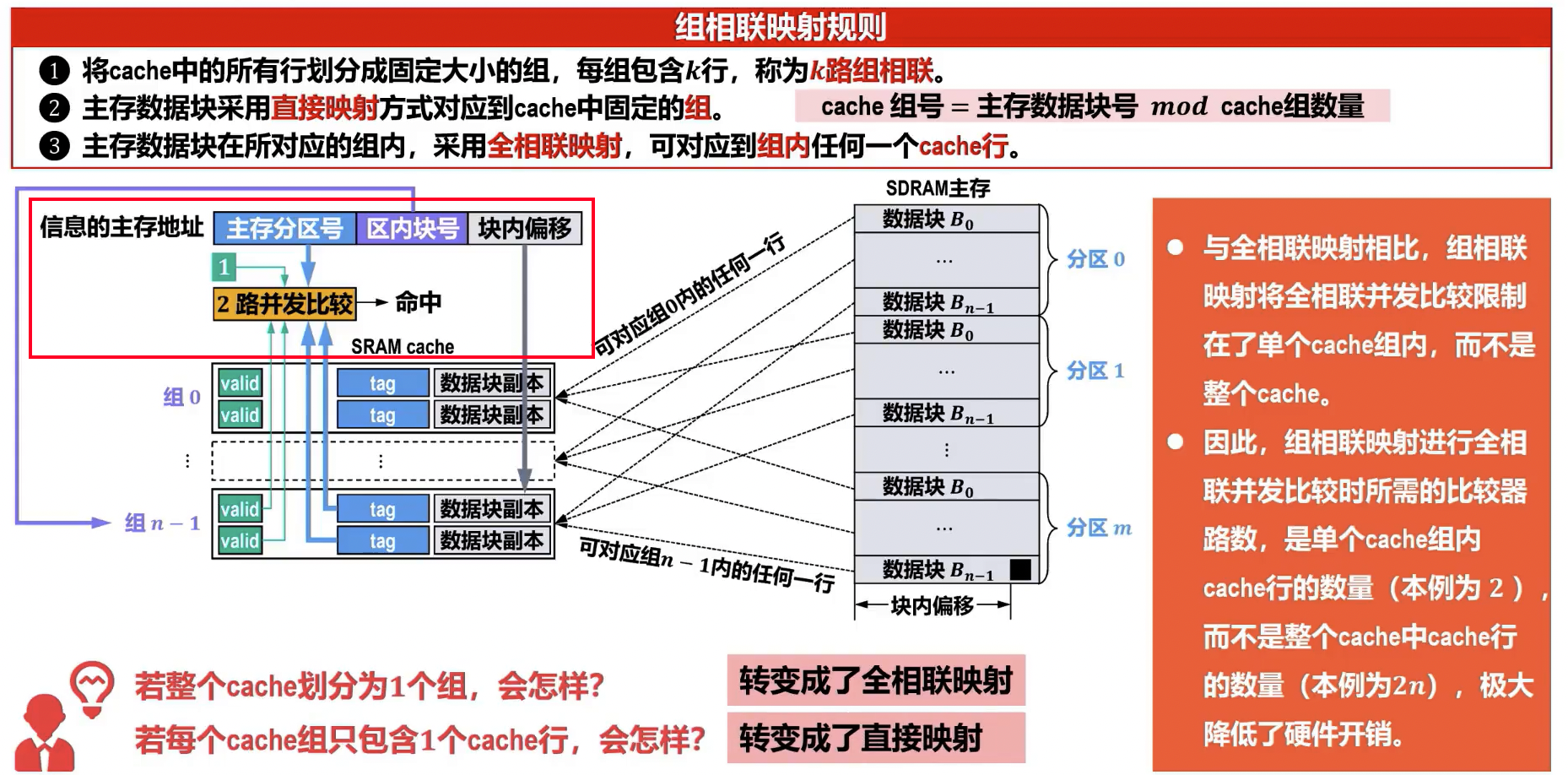
- 查找过程:
- 地址解析: CPU 生成的主存地址首先被划分为三个部分:
- 组号 (Set Index):用于确定主存块可能映射到的 Cache 组。
- 数据块地址 (Tag):用于在 Cache 组内部唯一标识主存块。
- 块内地址 (Offset):用于在 Cache 块(行)内部定位具体的字或字节。
- 组定位: 利用主存地址中的组号部分,Cache 控制器可以直接且快速地定位到 Cache 中对应的特定组。这个过程类似于直接映射中根据索引定位 Cache 行。
- 并行比较: 一旦定位到目标 Cache 组,控制器会同时(并行地)执行以下操作:
- 对于该组内的所有 Cache 行,将其存储的
Tag值与主存地址中的Tag进行比较。 - 同时检查这些 Cache 行的有效位 (Valid Bit)。有效位为 1 表示该 Cache 行中的数据是有效的,可以被使用。
- 对于该组内的所有 Cache 行,将其存储的
- 命中判断:
- 如果在当前组内找到一个 Cache 行的
Tag与主存地址中的Tag匹配,并且该行的有效位为 1,则表示 Cache 命中 (Cache Hit)。 - 如果组内所有行的
Tag都不匹配,或者匹配的行的有效位为 0,则表示 Cache 不命中 (Cache Miss)。
- 如果在当前组内找到一个 Cache 行的
- 数据读取 (命中时): 如果命中,控制器会使用主存地址中的块内地址 (Offset) 部分,从匹配的 Cache 行中取出所需的数据(字或字节),并将其发送给 CPU。
- 不命中处理 (不命中时): 如果不命中,Cache 控制器会暂停 CPU 的执行,然后从主存中将请求的数据块读取到 Cache 中。具体放入哪一行,需要根据替换策略(如 LRU、FIFO 等)来决定。数据载入 Cache 后,再将所需数据发送给 CPU,并更新对应的
Tag和有效位。
- 地址解析: CPU 生成的主存地址首先被划分为三个部分:
- 计算
- 主存分区数量
- 分区内数据块数量 (cache 组数)
- 数据块大小 字节
- 主存容量 字节
- cache组所包含cache行的数量 (记为 ),决定了数据块冲突的概率和全相联并发比较的复杂性。
- 越大,则发生数据块冲突的概率越低,但全相联并发比较电路越复杂。
- 选取适当的 ,可使组相联映射的硬件开销比全相联映射的硬件开销低很多,而性能上仍可接近全相联方式。
- 早期 cache 容量不大,通常 = 2 或 4,即 2 路或 4 路组相联比较常用。随着技术的发展,cache 容量不断增大, 的值也随之增大,目前很多处理器的 cache 采用 8 路或 16 路组相联。
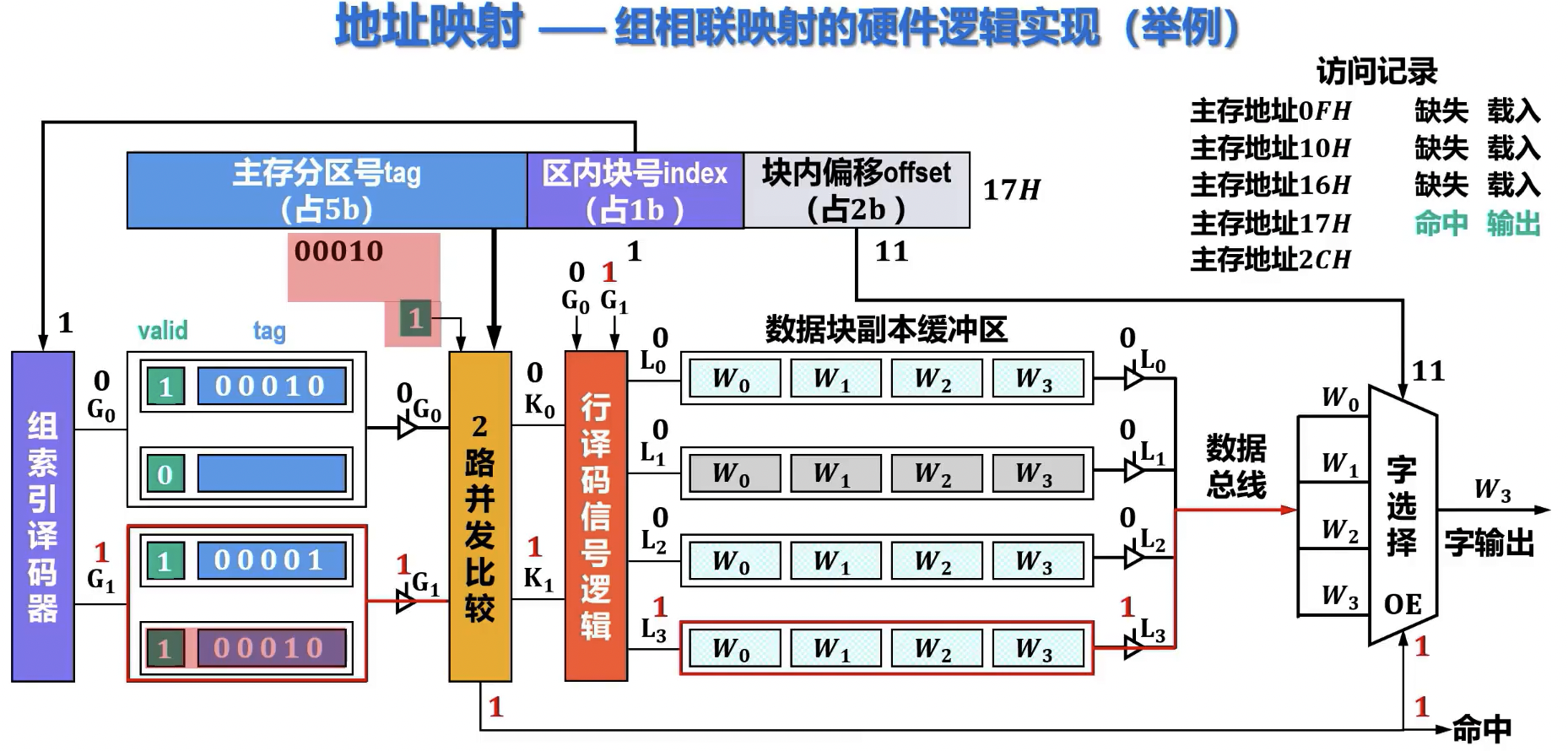
硬件逻辑实现
总结
- 一个主存数据块对应的 cache 行的数量,称为关联度。
- 直接映射方式的关联度为 1
- 全相联映射方式的关联度为 cache 的总行数
- k 路组相联映射方式的关联度为 k
- 关联度与命中率、命中时间、cache 行中标记 tag 所占空间 (额外开销) 的关系如下。
- 前提条件:
- cache 容量相同
- 主存数据块大小相同
- 关联度越低,命中率越低。因此,直接映射方式的命中率最低,全相联映射方式的命中率最高。
- 关联度越低,判断是否命中的开销越小,命中时间越短。因此,直接映射方式的命中时间最短,全相联映射的命中时间最长。
- 关联度越低,cache 行中标记 tag 所占空间 (额外开销) 越少。因此,直接映射方式的额外空间开销最少,全相联映射方式的额外空间开销最大。
- 前提条件:
例题
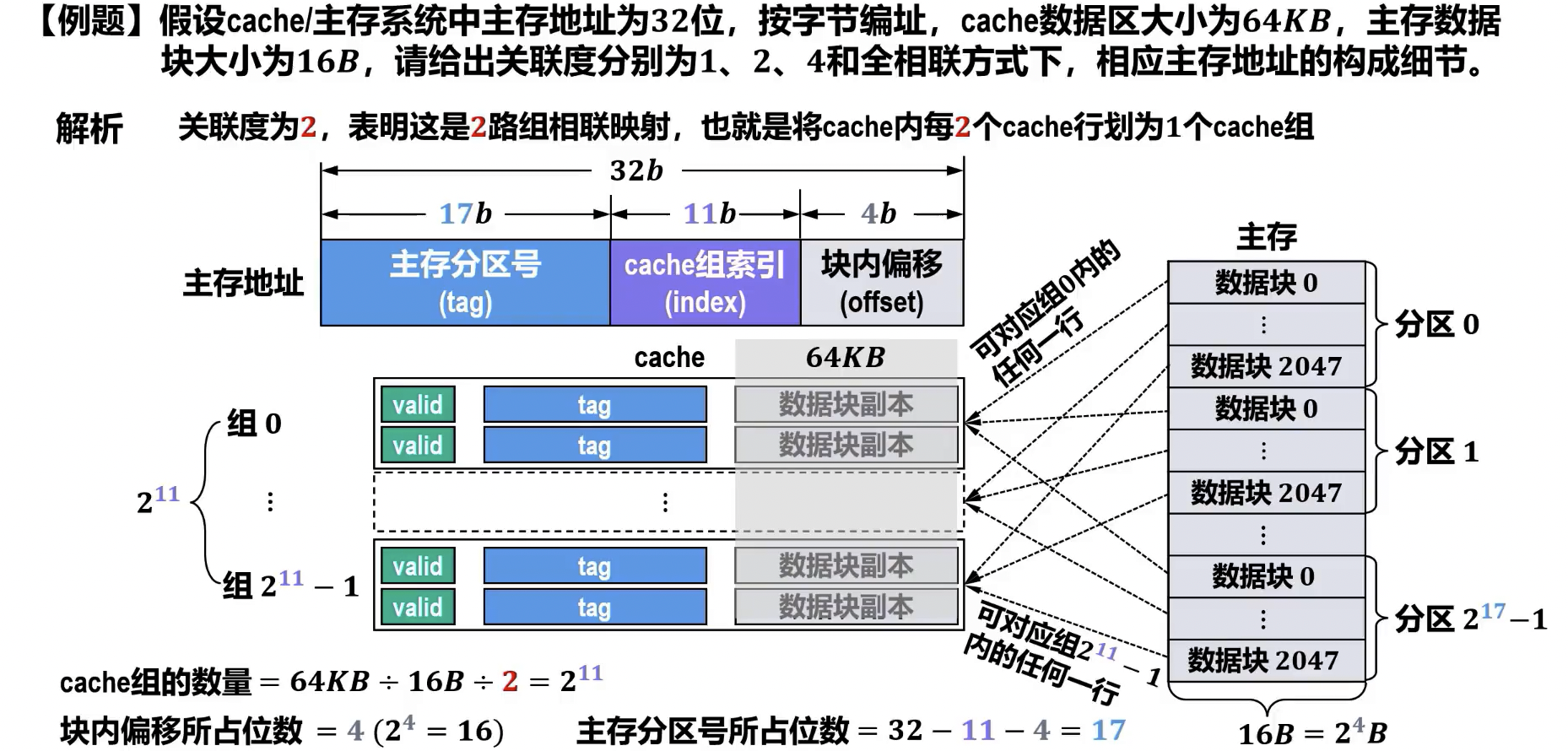
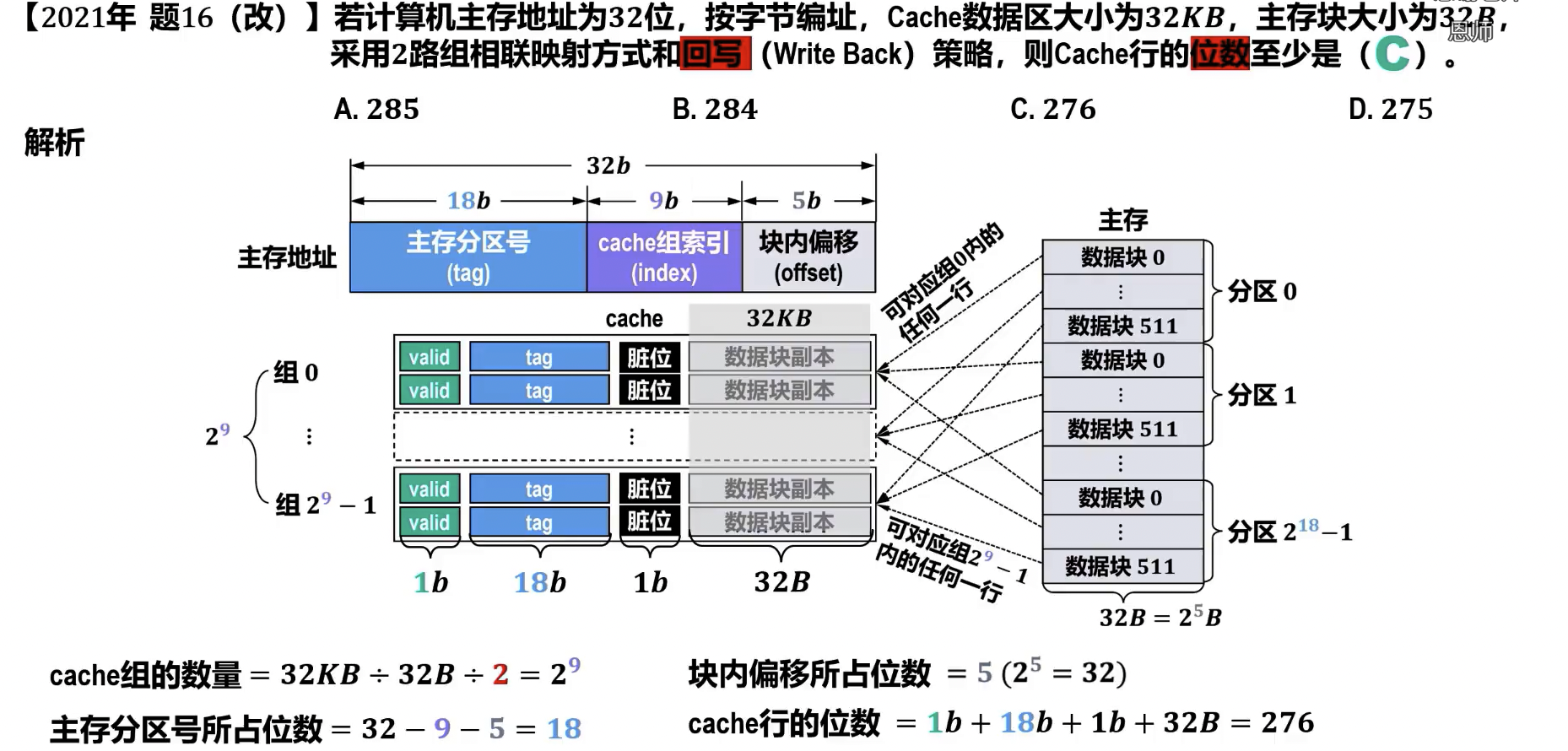
- cache 数据区 , 主存块大小 cache 行数
- cache 行数 , 路组相联 cache 组数 ()
- 主存地址 位,cache 组 位,主存块 位 tag 位
- valid 位,tag 位,dirty 位,主存块 cache 行 位
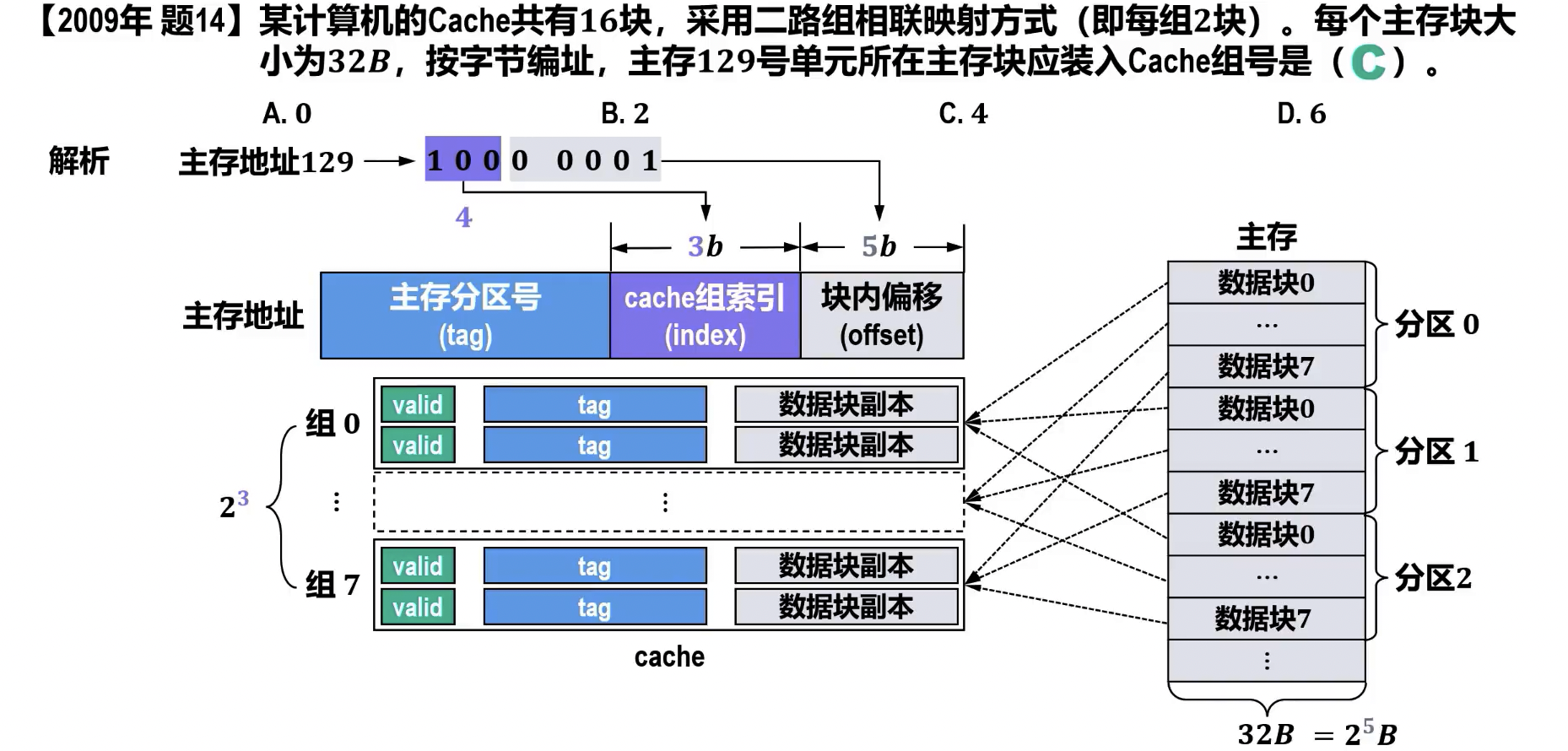
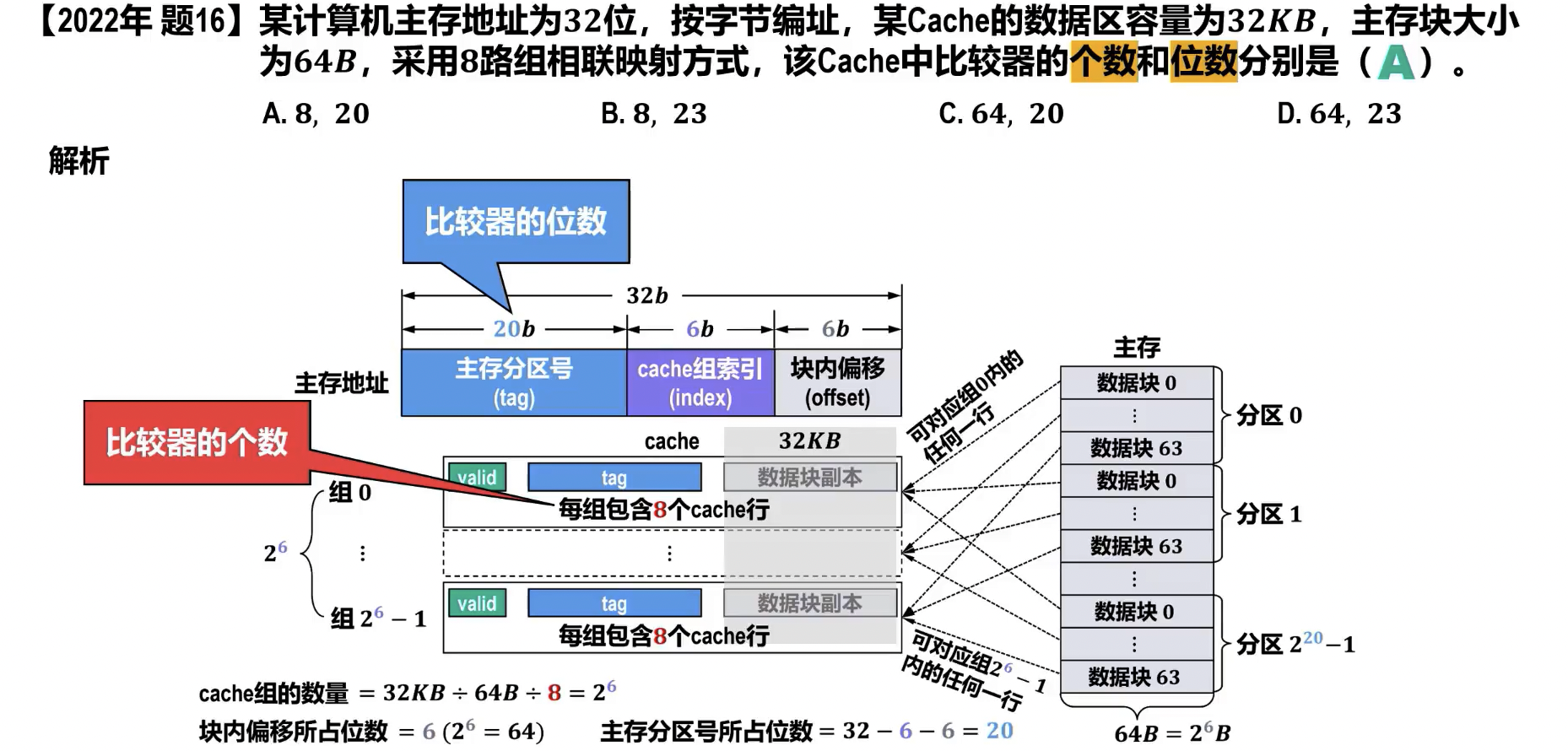
- 直接映射,每块只映射到唯一 cache 行,需要 1 个比较器
- r 路组相联映射,需要对应分组中与 r 个 cache 行比较,需要 r 个比较器
Cache 替换算法
使用替换算法的条件
- 直接映射方式:不使用替换算法。由于每个主存块在 Cache 中只有一个固定映射位置,当该位置已被占用且发生块冲突时,只能直接替换旧块,无需选择替换策略。
- 全相联或组相联方式:需要使用替换算法。因为一个主存块可以映射到 Cache 中多个位置(全相联)或一个组内的多个位置(组相联),当发生块冲突时,需要依据特定策略选择替换哪个块。
- cache 未满时就有可能出现冲突
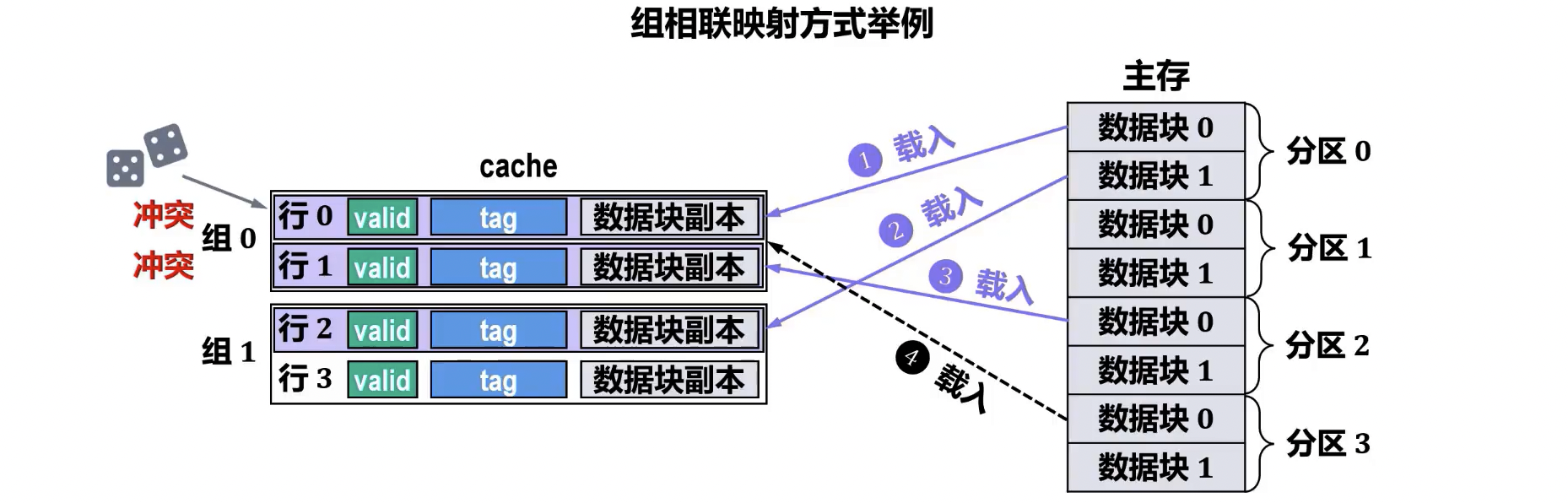
- cache 未满时就有可能出现冲突
常用替换算法
- 随机算法 (RAND) ^621bc7
- 原理:随机选择一个块进行替换。
- 特点:
- 优点:实现最简单,速度最快。
- 缺点:完全不考虑程序局部性,性能不稳定,可能较低。
- 随着 cache 容量的增大,随机替换算法的负面影响会减小。
- 先进先出算法 (FIFO, First-In, First-Out)
- 原理:选择在 Cache 中驻留时间最长的块(即最先进入 Cache 的块)进行替换。
- 特点:
- 优点:实现简单,只需记录每个 cache 行载入主存数据块的时刻或使用队列结构。
- 缺点:未考虑块的实际使用频率,可能将经常使用的块替换出去,导致命中率不高,存在 Belady 现象(增加 Cache 容量反而可能导致命中率下降)。
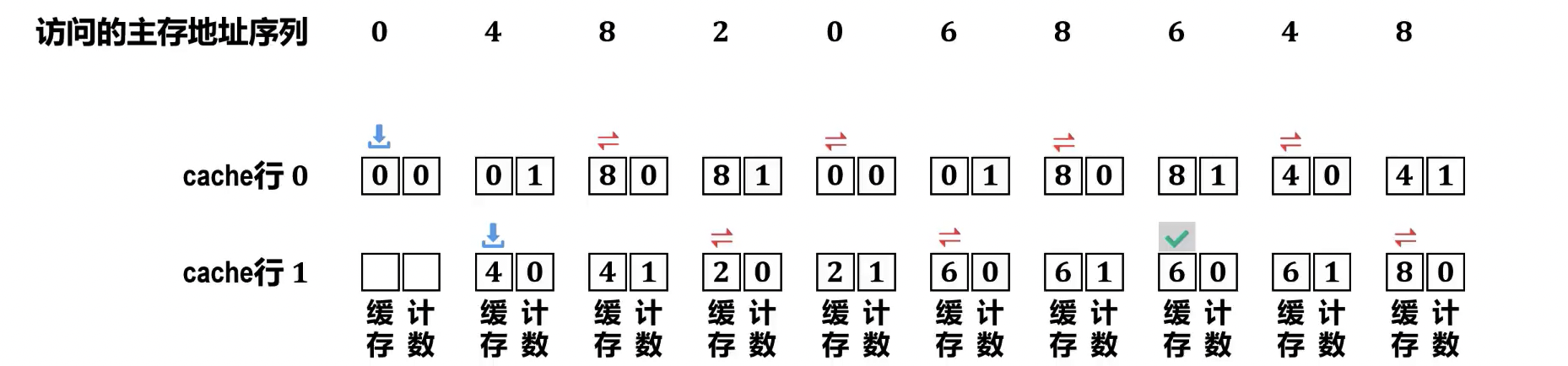
- 最近最少使用算法 (LRU, Least Recently Used)
- 原理:选择在最近一段时间内最久未被使用的块进行替换。该算法基于时间局部性原理。与 LFU 算法类似,也需要为每个 cache 行设置一个淘汰计数器。
- 不同点是:cache 行每被访问(载入/替换、命中)1 次,该 cache 行的计数器被清零, 其他计数值不为空的 cache 行各自的计数器被加 1。需要进行替换时,计数值最大的 cache 行被替换。
- 淘汰计数器的数值, 称为LRU 位, 其位数与 cache 组 (当只有 1 个组时, 则为全相联映射) 的大小有关。
- 理论上, n 路组相联 (即每个 cache 组包含 cache 行的数量为 n) 时LRU 位的位数 , 例如, 2 路组相联时LRU 位的位数为 1, 4 路组相联时LRU 位的位数为 2。
- 特点:
- 优点:符合程序运行的局部性原理,通常能获得较高的命中率。
- 缺点:实现复杂,硬件成本高(需要每行一个计数器),需要记录每个块的“年龄”(上次被访问的时间),例如使用时间戳、计数器或栈等数据结构,维护开销较大。
- 原理:选择在最近一段时间内最久未被使用的块进行替换。该算法基于时间局部性原理。与 LFU 算法类似,也需要为每个 cache 行设置一个淘汰计数器。
- 最不经常使用算法 (LFU, Least Frequently Used)
- 原理:选择在过去一段时间内访问次数最少的块进行替换。需要为每个 cache 行设置一个淘汰计数器,新载入的 cache 行从 0 开始计数,每命中访问 1 次,被访问 cache 行的淘汰计数器加 1。替换时,计数值最小的 cache 行被替换。
- 特点:
- 优点:考虑了块的访问频率,对访问频率高的块有较好的保留作用。
- 缺点:实现复杂,需要为每个块设置访问计数器,并且要周期性地更新或清零计数器;不能严格反映出近期的访问情况,新进入 Cache 的块可能因计数低而很快被替换。

- 优化替换算法 (OPT/MIN, Optimal)
- 原理:选择未来最长时间内不再被访问的块进行替换。
- 特点:
- 优点:理论上能达到最高的命中率,是衡量其他替换算法性能的基准。
- 缺点:无法实现,因为它需要预知未来的访问序列,在实际系统中不可用。
习题

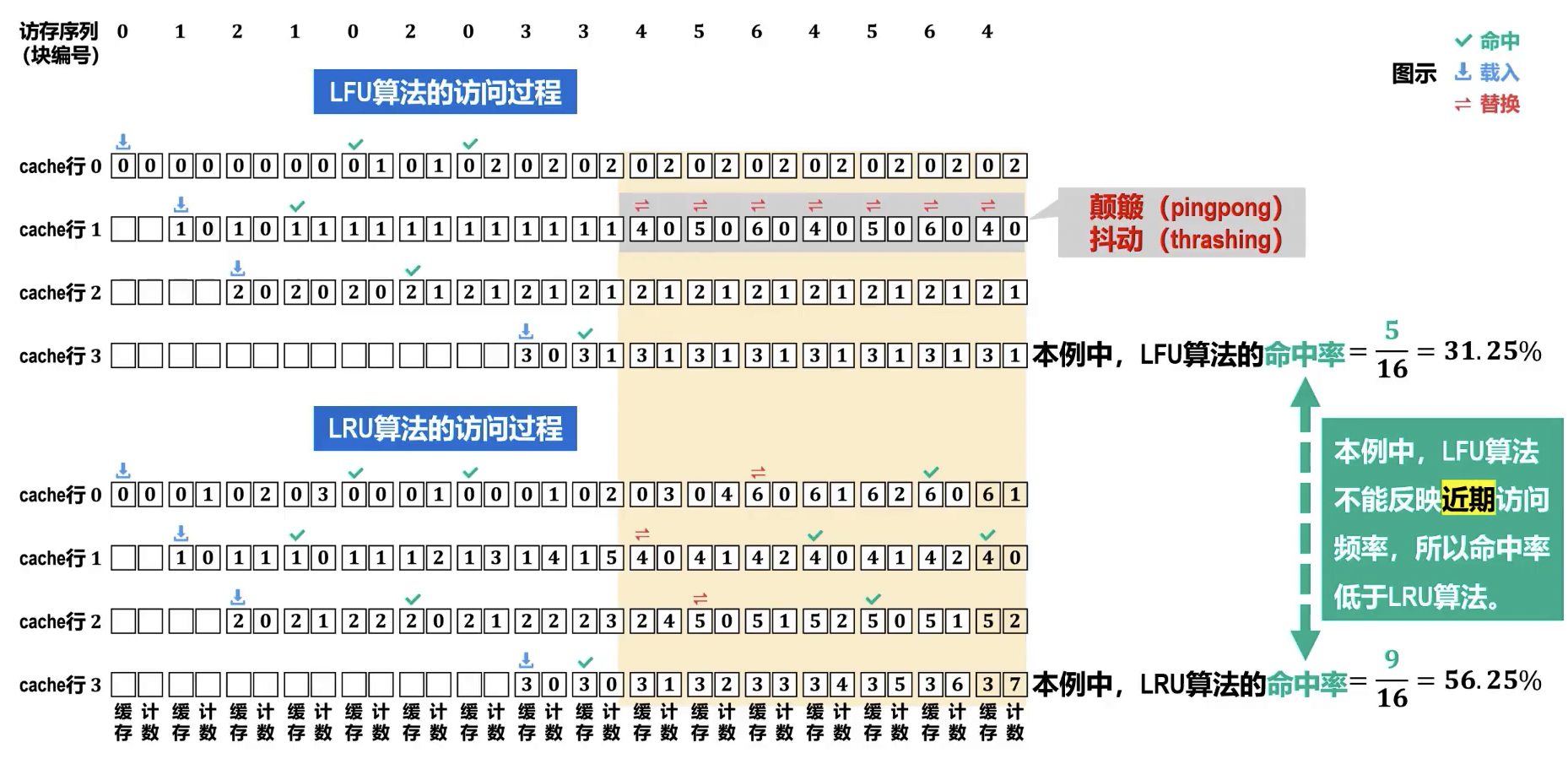
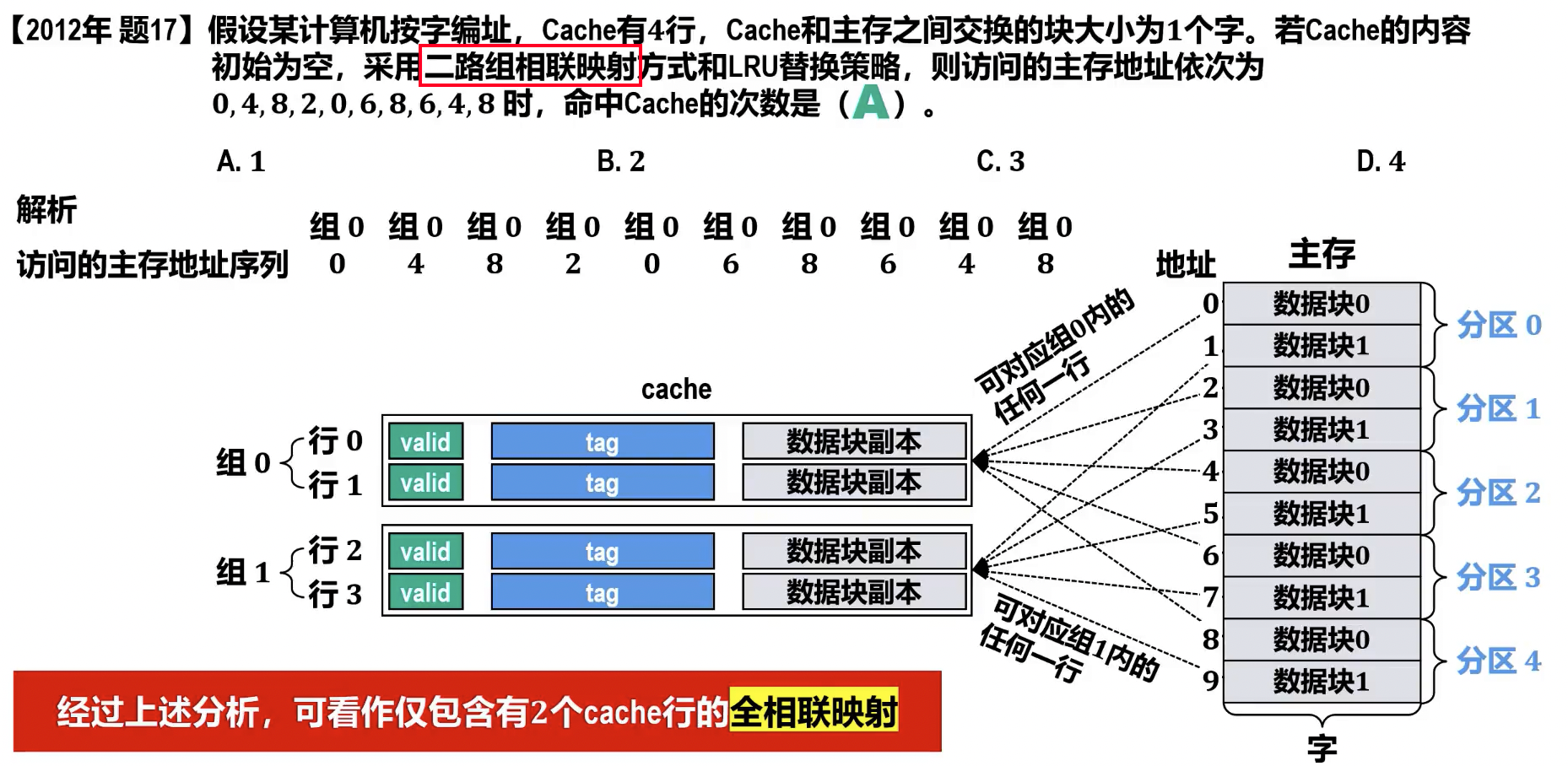
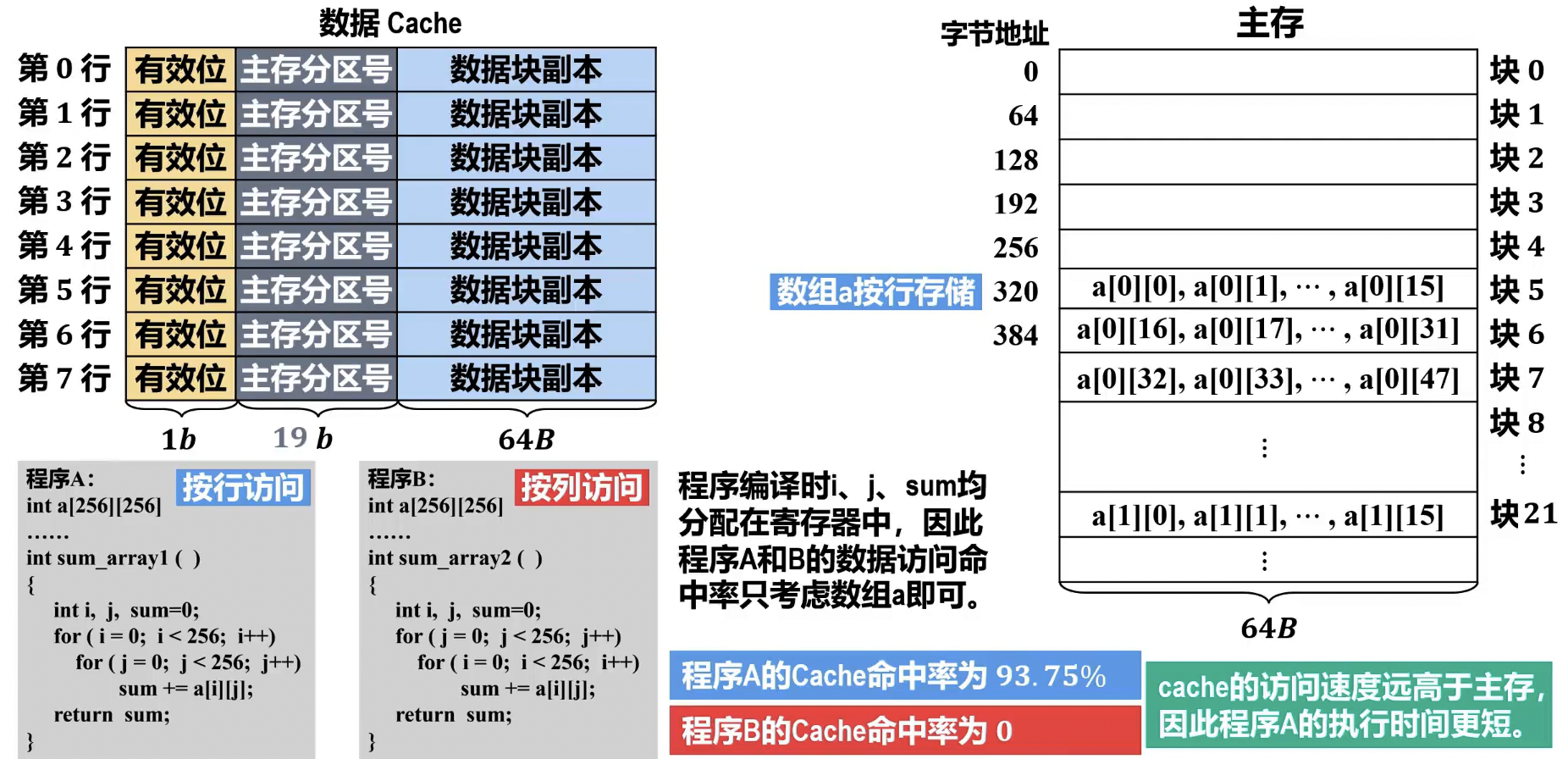
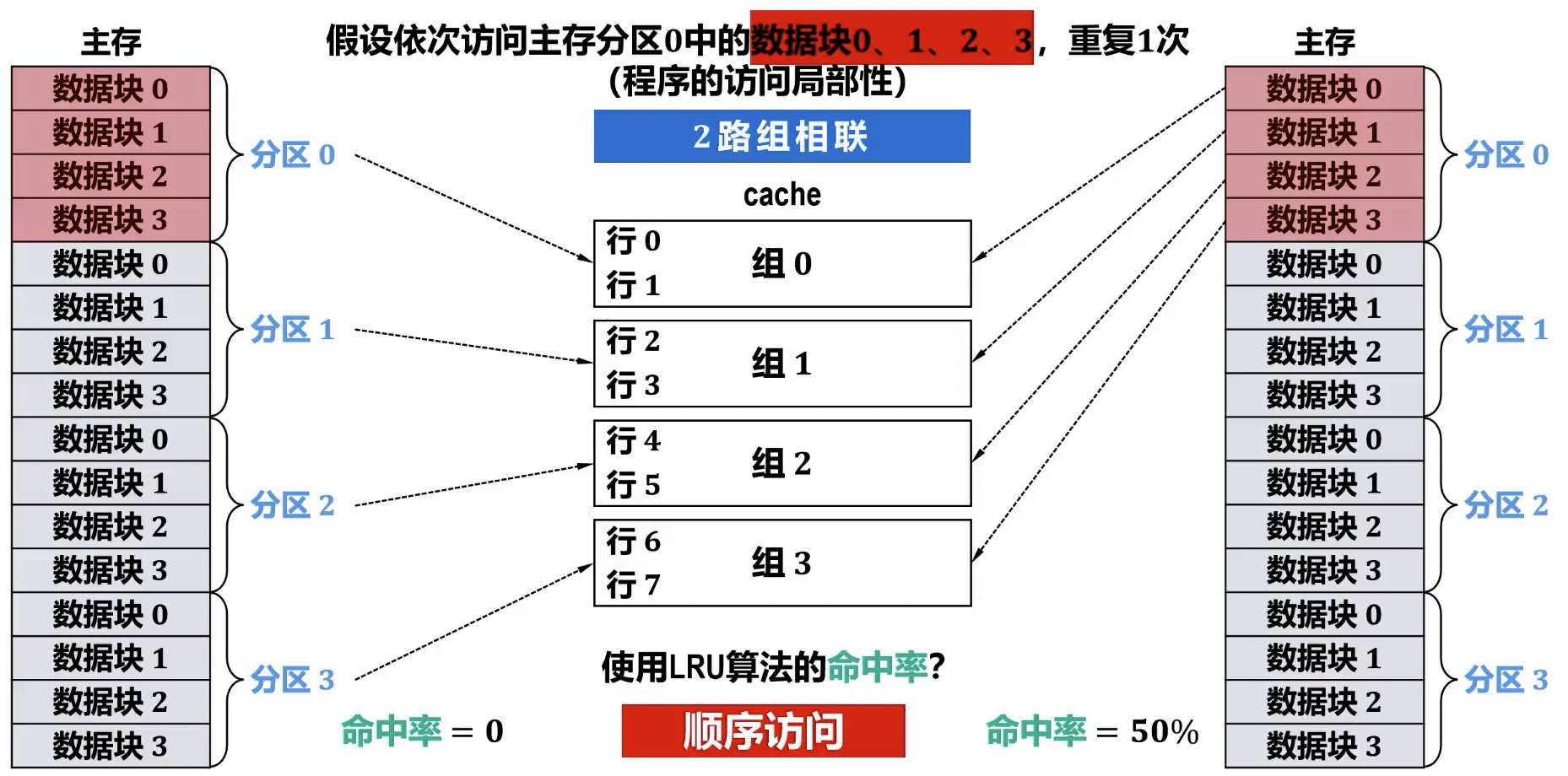
组相联分组顺序问题,应采用 mod 组数的方法,这样对顺序访问的优化更好

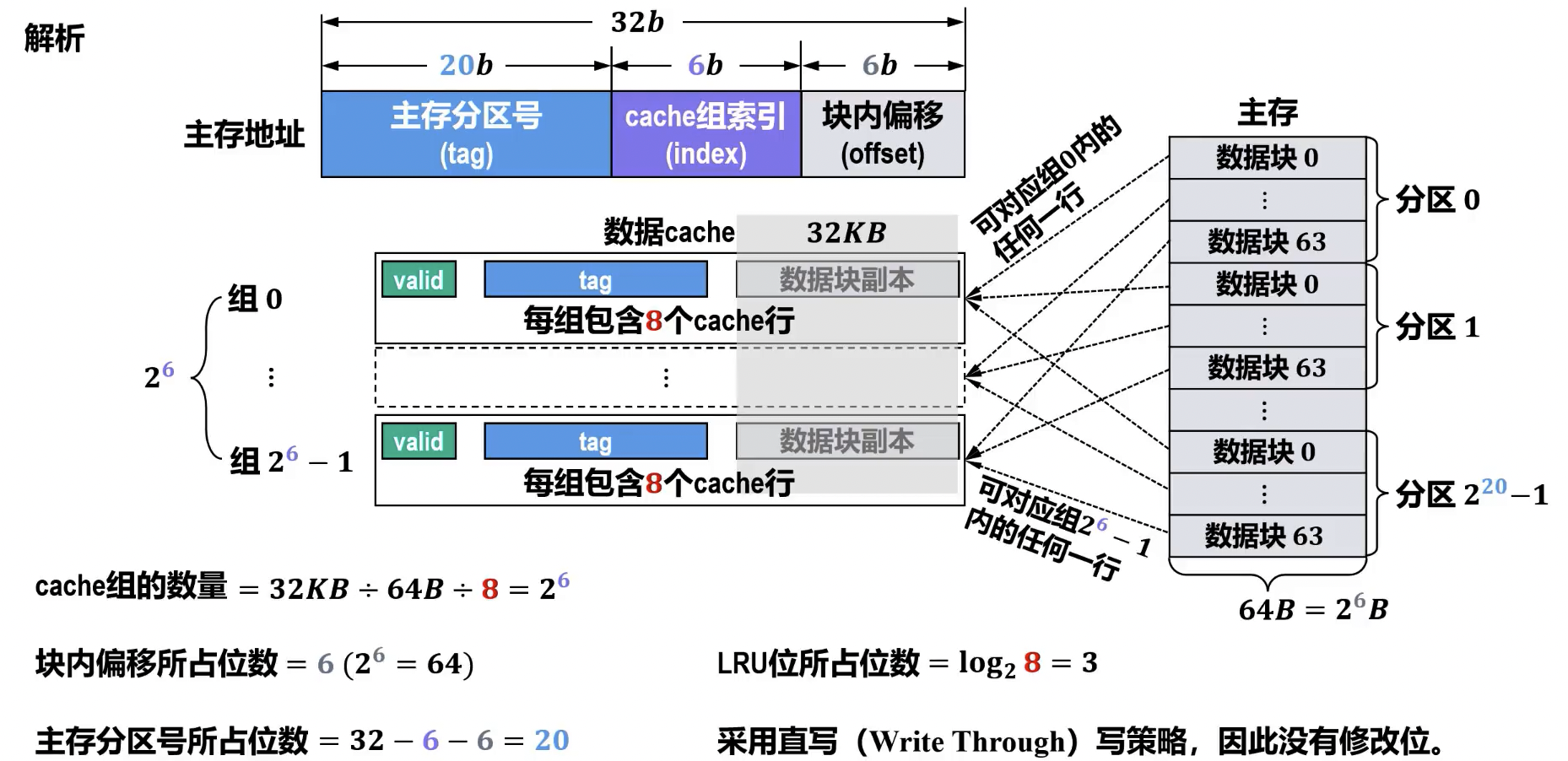
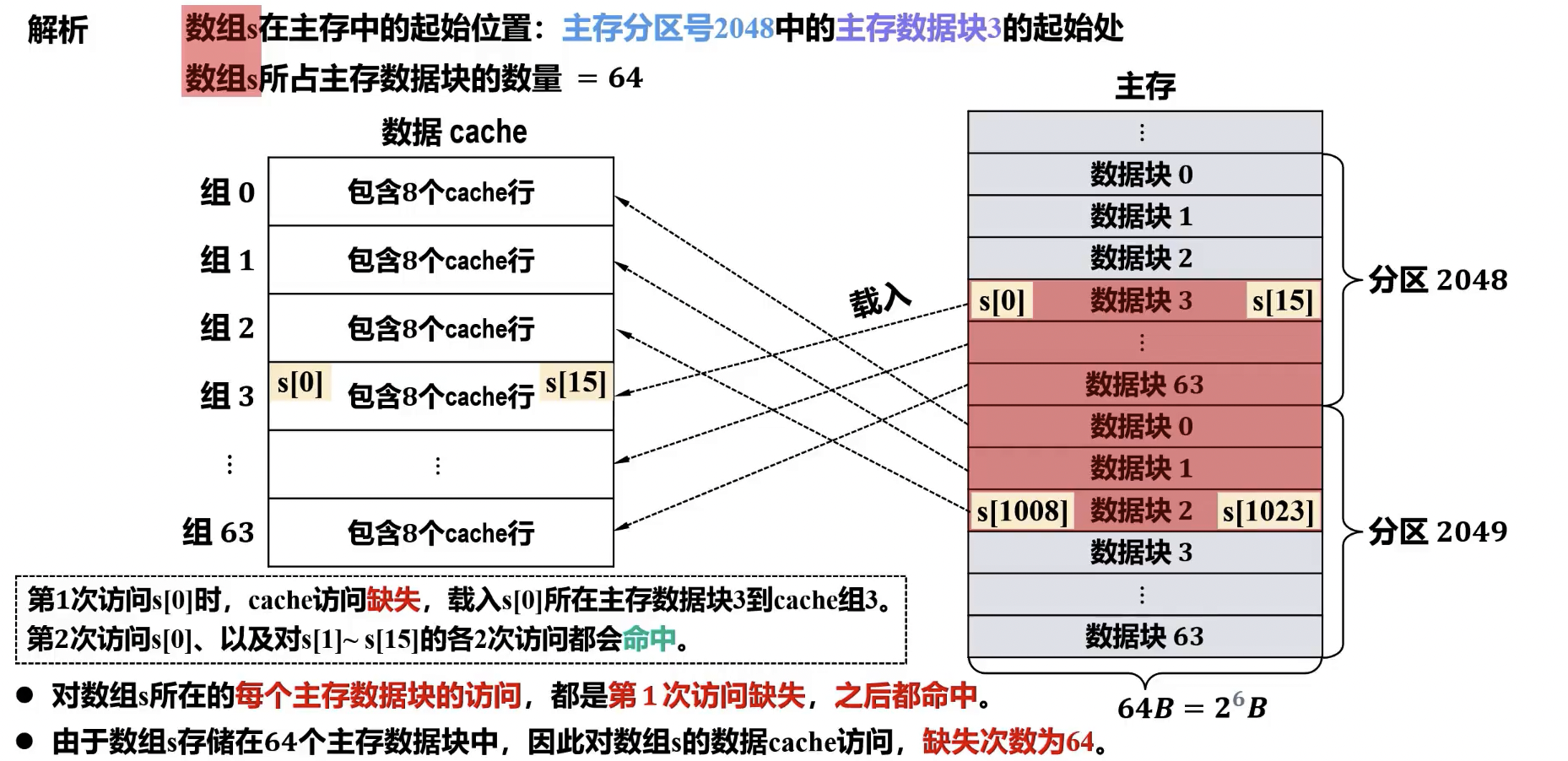
Cache 写入策略

- 写命中 (Write Hit) 策略
- 写直达 (Write-Through)
- 定义:数据同时写入 Cache 和主存。
- 特点:
- Cache 与主存的数据始终保持一致。
- 每次写操作都访问主存,写速度相对较慢。
- 通常配合写缓冲 (Write Buffer) 以提高写操作的效率。
- 优点:数据一致性维护简单。
- 缺点:写操作性能受主存速度限制,可能导致总线瓶颈。
- 写回 (Write-Back)
- 定义:数据只写入 Cache,不立即写入主存。Cache 块被修改后,其对应的“脏位” (Dirty Bit) 置 1。
- 特点:
- 仅当被替换的 Cache 块的“脏位”为 1 时,才将其写回主存。
- 写操作速度快,减少了主存访问次数。
- 优点:写操作性能高,减轻了主存总线负载。
- 缺点:数据一致性维护复杂(需处理 Cache 与主存、多 Cache 之间的一致性问题),系统掉电可能导致数据丢失。
- 是现代高性能处理器常用的写策略。
- 写直达 (Write-Through)

- 写不命中 (Write Miss) 策略
- 写分配 (Write-Allocate) / 读写 (Fetch on Write)
- 定义:当发生写不命中时,将主存中对应的块调入 Cache,然后再更新 Cache 中的数据。
- 特点:
- 利用空间局部性,后续对该块的读写操作可能命中 Cache。
- 常与写回 (Write-Back) 策略配合使用。
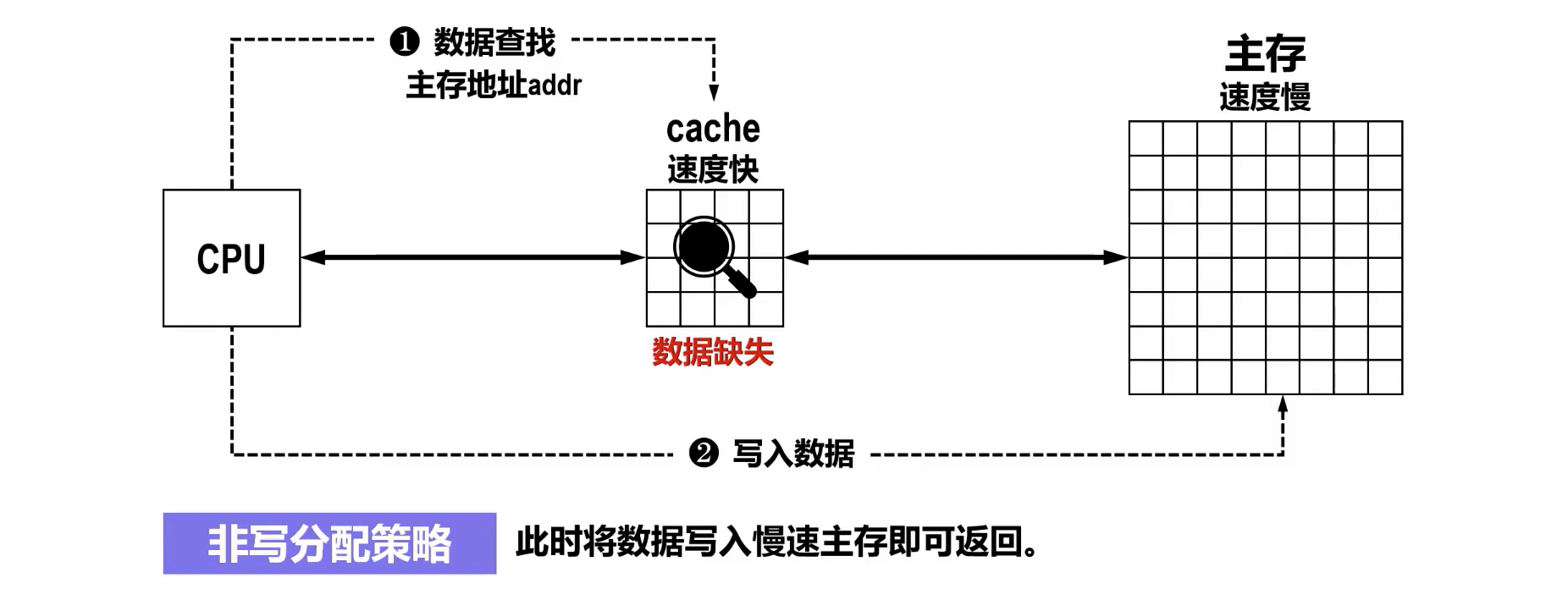
- 非写分配 (No-Write-Allocate) / 直写 (Write Around)
- 定义:当发生写不命中时,直接将数据写入主存,不将对应的块调入 Cache。
- 特点:
- 避免了不必要的 Cache 块调入和可能的冲突。
- 常与写直达 (Write-Through) 策略配合使用。

- 写分配 (Write-Allocate) / 读写 (Fetch on Write)
Cache 的分类和应用
TIP
了解即可, 由 AI 友情生成
- 硬件 cache
- 统一 cache
- 定义:指令和数据共用同一个缓存空间。
- 特点:
- 优点:灵活性高,能动态分配缓存空间给指令或数据,平均命中率可能更高。
- 缺点:取指令和取数据可能产生冲突,降低并行度。
- 应用:早期的 CPU 或某些特定场景。
- 分离 cache
- 定义:将缓存分为独立的指令缓存 (Instruction Cache, I-cache) 和数据缓存 (Data Cache, D-cache)。
- 特点:
- 优点:可同时进行指令读取和数据存取,提高 CPU 的并行处理能力和吞吐量。
- 缺点:设计相对复杂,可能存在空间利用率不高的情况(某一类缓存未满但另一类已满)。
- 应用:现代高性能 CPU 普遍采用 L1 级分离缓存。
- 多级 cache
- 定义:CPU 内部设置多层次的缓存结构,通常分为 L1、L2、L3。
- 目的:利用局部性原理,平衡速度与容量的矛盾,降低 CPU 访问主存的平均时间。
- 特点:
- L1 Cache (一级缓存):
- 最接近 CPU 核心。
- 容量最小(几 KB 到几十 KB),速度最快,与 CPU 同速。
- 通常为指令缓存和数据缓存分离(Split Cache),每个 CPU 核心独占。
- 用于存储 CPU 当前最频繁使用的数据和指令。
- L2 Cache (二级缓存):
- 介于 L1 和主存之间。
- 容量中等(几百 KB 到几 MB),速度次之。
- 通常是统一缓存(Unified Cache),可能由单个核心独占或多个核心共享。
- 用于存储 L1 未命中的数据和指令。
- L3 Cache (三级缓存):
- 介于 L2 和主存之间。
- 容量最大(几 MB 到几十 MB),速度最慢(相对 L1/L2)。
- 通常是统一缓存,由所有 CPU 核心共享。
- 用于存储 L2 未命中的数据和指令,减少对主存的访问。
- 访问顺序:CPU 首先访问 L1,若未命中则访问 L2,若 L2 仍未命中则访问 L3,最后才访问主存。
- L1 Cache (一级缓存):
- 统一 cache
- 软件 cache
- buffer cache (缓冲区缓存/磁盘缓存)
- 定义:操作系统在内存中开辟的一块区域,用于缓存磁盘数据块,加速磁盘 I/O 操作。
- 原理:
- 读操作:当进程请求读取数据时,操作系统首先检查数据是否在缓冲区缓存中。若命中,直接从内存返回;若未命中,则从磁盘读取到缓冲区,再返回给进程。
- 写操作:当进程写入数据时,数据首先写入缓冲区缓存,然后操作系统可以异步地将其写入磁盘(延迟写),减少磁盘 I/O 的阻塞。
- 应用:广泛应用于文件系统、数据库管理系统,提高系统性能和响应速度。
- web cache (Web 缓存/网络缓存)
- 定义:在 Web 通信过程中,将 Web 资源(如 HTML 页面、图片、CSS、JavaScript 文件等)的副本存储在靠近用户的存储介质中。
- 目的:
- 减少网络延迟:用户可以从更近的缓存获取资源,加快页面加载速度。
- 降低服务器负载:减轻源服务器的压力。
- 节省网络带宽:减少重复内容的传输。
- 类型及应用:
- 浏览器缓存 (Browser Cache): 用户浏览器本地存储的缓存,由浏览器自行管理。
- 代理服务器缓存 (Proxy Cache): 位于局域网或 ISP(互联网服务提供商)的代理服务器上,为多个用户提供缓存服务,共享缓存资源。
- CDN 缓存 (Content Delivery Network Cache): 内容分发网络,通过在全球部署大量边缘节点服务器,将内容分发到离用户最近的节点,提供更快的访问速度和更高的可用性。
- 协议:主要依赖 HTTP 协议的缓存机制,如
Cache-Control、Expires、Last-Modified、ETag等头部字段。
- buffer cache (缓冲区缓存/磁盘缓存)